
Hitachi Streaming Data Platform
Product Overview
MK-93HSDP003-04

© 2014 , 2016 Hitachi, Ltd. All rights reserved.
No part of this publication may be reproduced or transmitted in any form or by any means, electronic
or mechanical, including photocopying and recording, or stored in a database or retrieval system for
any purpose without the express written permission of Hitachi, Ltd.
Hitachi , Ltd., reserves the right to make changes to this document at any time without notice and
assumes no responsibility for its use. This document contains the most current information available
at the time of publication. When new or revised information becomes available, this entire document
will be updated and distributed to all registered users.
Some of the features described in this document might not be currently available. Refer to the most
recent product announcement for information about feature and product availability, or contact
Hitachi, Ltd., at
https://support.hds.com/en_us/contact-us.html.
Notice:Hitachi , Ltd. products and services can be ordered only under the terms and conditions of the
applicable Hitachi Data Systems Corporation agreements. The use of Hitachi , Ltd., products is
governed by the terms of your agreements with Hitachi Data Systems Corporation.
By using this software, you agree that you are responsible for:
1. Acquiring the relevant consents as may be required under local privacy laws or otherwise from
employees and other individuals to access relevant data; and
2. Verifying that data continues to be held, retrieved, deleted, or otherwise processed in
accordance with relevant laws.
Hitachi is a registered trademark of Hitachi, Ltd., in the United States and other countries. Hitachi
Data Systems is a registered trademark and service mark of Hitachi, Ltd., in the United States and
other countries.
Archivas, BlueArc, Essential NAS Platform, HiCommand, Hi-Track, ShadowImage, Tagmaserve,
Tagmasoft, Tagmasolve, Tagmastore, TrueCopy, Universal Star Network, and Universal Storage
Platform are registered trademarks of Hitachi Data Systems Corporation.
AIX, AS/400, DB2, Domino, DS6000, DS8000, Enterprise Storage Server, ESCON, FICON, FlashCopy,
IBM, Lotus, MVS, OS/390, RS/6000, S/390, System z9, System z10, Tivoli, VM/ESA, z/OS, z9, z10,
zSeries, z/VM, and z/VSE are registered trademarks and DS6000, MVS, and z10 are trademarks of
International Business Machines Corporation.
Microsoft is either a registered trademark or a trademark of Microsoft Corporation in the United States
and/or other countries.
Linux(R) is the registered trademark of Linus Torvalds in the U.S. and other countries.
Oracle and Java are registered trademarks of Oracle and/or its affiliates.
Red Hat is a trademark or a registered trademark of Red Hat Inc. in the United States and other
countries.
SL, RTView, SL Corporation, and the SL logo are trademarks or registered trademarks of Sherrill-
Lubinski Corporation in the United States and other countries.
SUSE is a registered trademark or a trademark of SUSE LLC in the United States and other countries.
RSA and BSAFE are either registered trademarks or trademarks of EMC Corporation in the United
States and/or other countries.
Windows is either a registered trademark or a trademark of Microsoft Corporation in the United States
and/or other countries.
All other trademarks, service marks, and company names in this document or website are properties
of their respective owners.
Microsoft product screen shots are reprinted with permission from Microsoft Corporation.
Notice on Export Controls. The technical data and technology inherent in this Document may be
subject to U.S. export control laws, including the U.S. Export Administration Act and its associated
regulations, and may be subject to export or import regulations in other countries. Reader agrees to
comply strictly with all such regulations and acknowledges that Reader has the responsibility to obtain
licenses to export, re-export, or import the Document and any Compliant Products.
Third-party copyright notices
Hitachi Streaming Data Platform includes RSA BSAFE(R) Cryptographic software of EMC Corporation.
Portions of this software were developed at the National Center for Supercomputing Applications
(NCSA) at the University of Illinois at Urbana-Champaign.
2
Hitachi Streaming Data Platform

Regular expression support is provided by the PCRE library package, which is open source software, written by
Philip Hazel, and copyright by the University of Cambridge, England. The original software is available from
ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/
This product includes software developed by Andy Clark.
This product includes software developed by Ben Laurie for use in the Apache-SSL HTTP server project.
This product includes software developed by Daisuke Okajima and Kohsuke Kawaguchi (http://
relaxngcc.sf.net/).
This product includes software developed by IAIK of Graz University of Technology.
This product includes software developed by Ralf S. Engelschall <[email protected]> for use in the mod_ssl
project (http://www.modssl.org/).
This product includes software developed by the Apache Software Foundation (http://www.apache.org/).
This product includes software developed by the Java Apache Project for use in the Apache JServ servlet engine
project (http://java.apache.org/).
This product includes software developed by the University of California, Berkeley and its contributors.
This software contains code derived from the RSA Data Security Inc. MD5 Message-Digest Algorithm, including
various modifications by Spyglass Inc., Carnegie Mellon University, and Bell Communications Research, Inc
(Bellcore).
Java is a registered trademark of Oracle and/or its affiliates.
Export of technical data contained in this document may require an export license from the United States
government and/or the government of Japan. Contact the Hitachi Data Systems Legal Department for any
export compliance questions.
3
Hitachi Streaming Data Platform

4
Hitachi Streaming Data Platform

Contents
Preface................................................................................................. 9
1 What is Streaming Data Platform?.........................................................13
A data processing system that analyzes the "right now"............................................14
Streaming Data Platform features............................................................................18
High-speed processing of large sets of time-sequenced data................................18
Summary analysis scenario definitions that require no programming.................... 19
2 Hardware components......................................................................... 21
System components............................................................................................... 22
Components of Streaming Data Platform and Streaming Data Platform software
development kit..................................................................................................... 24
SDP servers........................................................................................................... 26
3 Software components.......................................................................... 29
Components used in stream data processing............................................................30
Stream data..................................................................................................... 30
Input and output stream queues........................................................................31
Tuple............................................................................................................... 31
Query.............................................................................................................. 32
Query group.....................................................................................................34
Window........................................................................................................... 34
Stream data processing engine..........................................................................34
Using CQL to process stream data...........................................................................35
Using definition CQL to define streams and queries............................................. 35
Using data manipulation CQL to specify operations on stream data...................... 35
C External Definition Function............................................................................36
Coordinator groups................................................................................................ 36
SDP broker and SDP coordinator............................................................................. 39
SDP manager.........................................................................................................41
Log notifications............................................................................................... 42
Restart feature................................................................................................. 43
5
Hitachi Streaming Data Platform

4 Data processing...................................................................................47
Filtering records..................................................................................................... 48
Extracting records.................................................................................................. 50
5 Internal adapters................................................................................. 53
Internal input adapters...........................................................................................54
TCP data input adaptor...........................................................................................54
Overview of the TCP data input adaptor............................................................. 54
Prerequisites for using the TCP input adaptor..................................................... 55
Input adaptor configuration of the TCP data input adaptor...................................55
User program that acts as data senders............................................................. 56
TCP data input connector.................................................................................. 56
Number of connections................................................................................56
TCP data format..........................................................................................57
Byte order of data....................................................................................... 60
Restart reception of TCP connection............................................................. 60
Setting for using the TCP data input adaptor................................................. 60
Comparison of supported functions.................................................................... 61
Inputting files........................................................................................................ 62
Inputting HTTP packets.......................................................................................... 63
Outputting to the dashboard...................................................................................63
Cascading adaptor..................................................................................................64
Cascading adaptor processing overview..............................................................66
Communication method.................................................................................... 67
Features...........................................................................................................68
Connection details............................................................................................ 73
Time synchronization settings............................................................................73
Internal output adapters.........................................................................................76
SNMP adaptor........................................................................................................77
SMTP adaptor........................................................................................................ 77
Distributed send connector..................................................................................... 77
Auto-generated adapters........................................................................................ 77
6 External adapters.................................................................................81
External input adapters...........................................................................................82
External output adapters........................................................................................ 82
External adapter library.......................................................................................... 83
Workflow for creating external input adapters.....................................................83
Workflow for creating external output adapters...................................................85
Creating callbacks.............................................................................................86
Connecting to parallel-processing SDP servers..........................................................87
Custom dispatchers................................................................................................87
Rules for creating class files...............................................................................88
Examples of implementing dispatch methods......................................................89
Heartbeat transmission...........................................................................................90
Troubleshooting..................................................................................................... 90
7 RTView Custom Data Adapter............................................................... 91
Setting up the RTView Custom Data Adapter............................................................92
6
Hitachi Streaming Data Platform

Environment setup................................................................................................. 92
Editing the system definition file..............................................................................93
Environment variable settings................................................................................. 95
Data connection settings.........................................................................................95
Uninstallation.........................................................................................................98
File list.................................................................................................................. 98
Operating the RTView Custom Data Adapter............................................................ 98
Types of operations...........................................................................................98
Operation procedure......................................................................................... 99
Starting the RTView Custom Data Adapter..........................................................99
Stopping the RTView Custom Data Adapter.......................................................100
8 Scale-up, scale-out, and data-parallel configurations.............................103
Data-parallel configurations...................................................................................104
Scale-up configuration.....................................................................................104
Scale-out configuration....................................................................................106
Data-parallel settings............................................................................................107
9 Data replication................................................................................. 109
Examples of using data replication.........................................................................110
Data-replication setup...........................................................................................111
10 Setting parameter values in definition files........................................... 113
Relationship between parameters files and definition files........................................114
Examples of setting parameter values in query-definition files and query-group
properties files..................................................................................................... 116
Adapter schema automatic resolution.................................................................... 117
11 Logger.............................................................................................. 123
Log-file generation............................................................................................... 124
Glossary................................................................................................1
7
Hitachi Streaming Data Platform

8
Hitachi Streaming Data Platform

Preface
This manual provides an overview and a basic understanding of Hitachi
Streaming Data Platform (Streaming Data Platform). It is intended to provide
an overview of the features and system configurations of Streaming Data
Platform, and to give you the basic knowledge needed to set up and operate
such a system.
This preface includes the following information:
Intended audience
This document is intended for solution developers and integration developers.
Product version
This document revision applies to Streaming Data Platform version 3.0 or
later.
Release notes
Read the release notes before installing and using this product. They may
contain requirements or restrictions that are not fully described in this
document or updates or corrections to this document. The latest release
notes are available on Hitachi Data Systems Support Connect:
https://
support.hds.com/en_us/documents.html.
Referenced documents
Hitachi Streaming Data Platform documents:
• Hitachi Streaming Data Platform Getting Started Guide, MK-93HSDP006
• Hitachi Streaming Data Platform Setup and Configuration Guide,
MK-93HSDP000
• Hitachi Streaming Data Platform Application Development Guide,
MK-93HSDP001
• Hitachi Streaming Data Platform Messages, MK-93HSDP002
Preface 9
Hitachi Streaming Data Platform

Hitachi Data Systems Portal, http://portal.hds.com
Document conventions
This document uses the following terminology conventions:
Abbreviation Full name or meaning
HSDP Hitachi Streaming Data Platform
Streaming Data
Platform
HSDP software
development kit
Hitachi Streaming Data Platform software development kit
Streaming Data
Platform software
development kit
Java Java
™
JavaVM Java
™
Virtual Machine
Linux
• Red Hat Enterprise Linux
®
• SUSE Linux Enterprise Server
This document uses the following typographic conventions:
Convention
Description
Regular text bold In text: keyboard key, parameter name, property name, hardware labels,
hardware button, hardware switch
In a procedure: user interface item
Italic Variable, emphasis, reference to document title, called-out term
Screen text
Command name and option, drive name, file name, folder name, directory
name, code, file content, system and application output, user input
< > angled brackets Variable (used when italic is not enough to identify variable)
[ ] square brackets Optional value
{ } braces Required or expected value
| vertical bar Choice between two or more options or arguments.
... The item preceding this symbol can be repeated as needed.
This document uses the following icons to draw attention to information:
Icon
Label Description
Note Calls attention to important or additional information.
10 Preface
Hitachi Streaming Data Platform

Icon Label Description
Tip Provides helpful information, guidelines, or suggestions for performing
tasks more effectively.
Caution Warns the user of adverse conditions or consequences (for example,
disruptive operations).
Warning Warns the user of severe conditions or consequences (for example,
destructive operations).
Getting help
Hitachi Data Systems Support Connect is the destination for technical support
of products and solutions sold by Hitachi Data Systems. To contact technical
support, log on to Hitachi Data Systems Support Connect for contact
information:
https://support.hds.com/en_us/contact-us.html.
Hitachi Data Systems Community is a global online community for HDS
customers, partners, independent software vendors, employees, and
prospects. It is the destination to get answers, discover insights, and make
connections. Join the conversation today! Go to
community.hds.com,
register, and complete your profile.
Comments
Please send us your comments on this document to
Include the document title and number, including the revision level (for
example, -07), and refer to specific sections and paragraphs whenever
possible. All comments become the property of Hitachi Data Systems
Corporation.
Thank you!
Preface 11
Hitachi Streaming Data Platform

12 Preface
Hitachi Streaming Data Platform

1
What is Streaming Data Platform?
Streaming Data Platform is a product that enables you to process stream
data; that is, it allows you to analyze in real-time large sets of data as they
are being created. This chapter provides an overview of Streaming Data
Platform and explains its features. This chapter also gives an example of
adding Streaming Data Platform to your current workflow, and it describes
the system configuration needed to set up and run Streaming Data Platform.
□
A data processing system that analyzes the "right now"
□
Streaming Data Platform features
What is Streaming Data Platform? 13
Hitachi Streaming Data Platform

A data processing system that analyzes the "right now"
Our societal infrastructure has been transformed by the massive amounts of
data being packed into our mobile telephones, IC cards, home appliances,
and other electronic devices. As a result, the amount of data handled by data
processing systems continues to grow daily. The ability to quickly summarize
and analyze this data can provide us with valuable new insights. To be useful,
any real-time data processing system must have the ability to create new
value from the massive amounts of data that is being created every second.
Streaming Data Platform responds to this challenge by giving you the ability
to perform stream data processing. Stream data processing gives you real-
time summary analysis of the large quantities of time-sequenced data that is
always being generated, as soon as the data is generated.
For example, think how obtaining real-time summary information on what
was searched for from peoples PCs and mobile phones could increase your
product sales opportunities. If a particular product becomes a hot topic on
product discussion sites, you expect the demand for it to increase, so more
people would tend to search for that product on the various search sites. You
can identify such products by using stream data processing to analyze the
number of searches in real-time and provide summary results. This
information allows retail outlets to increase their orders for the product
before the demand hits, and for the manufacturer to quickly ramp up
production of the product.
On the IT systems side, demand for higher operating efficiencies and lower
costs continues to grow. At the same time, the increasing use of virtualization
and cloud computing results in ever larger and more complex systems,
making it even more difficult for IT to get a good overview of their system's
state of operation. This means that it often takes too long to detect and
resolve problems when they occur. Now, by using stream data processing to
monitor the operating state of the system in real-time, a problem can be
quickly dealt with as soon as it occurs. Moreover, by analyzing trends and
correlations in the information about the system's operations, warning signs
can be detected, which can be used to prevent errors from ever occurring.
Adding Streaming Data Platform to your data processing system gives you a
tool that is designed for processing these large volumes of data.
The following figure provides an overview of a configuration that uses
Streaming Data Platform to implement stream data processing.
14 What is Streaming Data Platform?
Hitachi Streaming Data Platform

Figure 1 Overview of a stream data processing configuration that uses
Streaming Data Platform
Introducing Streaming Data Platform into your stream data processing
system allows you to perform summary analysis of data as it is being
created.
For example, by using a stream data processing system to monitor system
operations, you can summarize and analyze log files output by a server and
HTTP packets sent over a network. These results can then be outputted to a
file, allowing you to monitor your system's operations in real-time. In this
way, you can quickly resolve system problems as they occur, improving
operation and maintenance efficiencies. You can also store the processing
results in a file, allowing you to use other applications to further review or
process the results.
To give you a better idea of how stream data processing carries out real-time
processing, stream data processing is compared to conventional stored data
processing in the following example.
Figure 2 Stored data processing on page 16 shows conventional stored
data processing.
What is Streaming Data Platform? 15
Hitachi Streaming Data Platform

Figure 2 Stored data processing
Data processed using stored data begins by storing the data sequentially in a
database as it occurs. Processing is not actually performed until a user issues
a query for the data stored in the database, and summary analysis results
are returned. Because data that is already stored in a database is searched
when the query is received, there is a time lag between the time the data is
collected and the time the data summary analysis results are produced. In
the figure, processing of data that was collected at 09:00:00 is performed by
a query issued at 09:05:00, obviously lagging behind the time the data was
collected.
Figure 3 Stream data processing on page 17 shows stream data
processing.
16 What is Streaming Data Platform?
Hitachi Streaming Data Platform

Figure 3 Stream data processing
With stream data processing, you pre-load a query (summary analysis
scenario) that will perform incremental data analysis, thus minimizing the
amount of computing that is required. Moreover, because data analysis is
triggered by the data being input, there is no time lag between it and the
time the data is collected, providing you with real-time data summary
analysis. This kind of stream data processing, in which processing is triggered
by the input data itself, is a superior approach for data that is generated
sequentially.
Therefore, the ability to perform stream data processing that you gain by
integrating Streaming Data Platform into your system allows you to get a
real-time summary and analysis of the data.
What is Streaming Data Platform? 17
Hitachi Streaming Data Platform

Streaming Data Platform features
Streaming Data Platform has the following features:
• High-speed processing of large sets of time-sequenced data
• Summary analysis scenario definitions that require no programming
The following subsections explain these features.
High-speed processing of large sets of time-sequenced data
Streaming Data Platform uses both in-memory processing and incremental
computational processing, which allows it to quickly process large sets of
time-sequenced data.
In-memory processing
With in-memory processing, data is processed while it is still in memory, thus
eliminating unnecessary disk access.
When processing large data sets, the time required to perform disk I/O can
be significant. By processing data while it is still in memory, Streaming Data
Platform avoids excess disk I/O, enabling data to be processed faster.
Incremental computational processing
With incremental computational processing, a pre-loaded query is processed
iteratively when triggered by the input data, and the processing results are
available for the next iteration. This means that the next set of computations
does not need to process all of the target data elements; only those elements
that have changed need to be processed.
The following figure shows incremental computation on stream data as
performed by Streaming Data Platform.
18 What is Streaming Data Platform?
Hitachi Streaming Data Platform

Figure 4 Incremental computation performed on stream data
As shown in the figure, when the first stream data element arrives,
Streaming Data Platform performs computational process 1. When the next
stream data element arrives, computational process 2 simply removes data
element 3 from the process range and adds data element 7 to the process
range, building on the results of computational process 1. This minimizes the
total processing required, thus enabling the data to be processed faster.
Summary analysis scenario definitions that require no programming
The actions performed in stream data processing are defined by queries that
are called summary analysis scenarios. Definitions for these summary
analysis scenarios are written in a language called CQL, which is very similar
to SQL, the standard language used to manipulate databases. This means
that you do not need to create a custom analysis application to create
summary analysis scenarios. Summary analysis scenarios can also be
modified simply by changing the definition files written in CQL.
Stream data processing actions written in CQL are called queries. In a single
summary analysis scenario, multiple queries can be coded.
For example, the following figure shows a summary analysis scenario written
in CQL for a temperature monitoring system that has multiple observation
sites, each with an assigned ID. The purpose of the query is to summarize
and analyze all of the below freezing point data found in the observed data
set.
What is Streaming Data Platform? 19
Hitachi Streaming Data Platform

Figure 5 Example of using CQL to write a summary analysis scenario
CQL is a general-purpose query language that can be used to specify a wide
range of processing. By combining multiple queries, you can define summary
analysis scenarios to handle a variety of operations.
20 What is Streaming Data Platform?
Hitachi Streaming Data Platform

2
Hardware components
This chapter provides information about the details of system components,
components of Streaming Data Platform and Streaming Data Platform
software development kit, and SDP servers.
□
System components
□
Components of Streaming Data Platform and Streaming Data Platform
software development kit
□
SDP servers
Hardware components 21
Hitachi Streaming Data Platform

System components
Hitachi Streaming Data Platform offers real-time processing of chronological
data (stream data) that is generated sequentially (in-memory). The stream
data is generated based on a user-defined (through CQL) analysis scenario
through CQL. The structure and components of SDP systems are
development server, data-transfer server, data-analysis server, and
dashboard server.
Example of an SDP system
Description
The components of Streaming Data Platform are as follows.
22 Hardware components
Hitachi Streaming Data Platform

Table 1 SDP system components
S. No. Component Description
1 Development server
• Streaming Data Platform and Streaming Data Platform
software development kit are installed on the
development server.
• This server provides a development environment for
analysis scenarios. It also provides a development
environment for adapters that send and receive the
stream data that is used by the SDP system.
• A system developer can use the API and tools provided
with Streaming Data Platform software development kit
to develop and test analysis scenarios and adapters.
2 Data-transfer server
• Streaming Data Platform is installed on the data-
transfer server.
• This server outputs stream data from a data source to
the data-analysis server.
• The output formats that are supported include text files
and HTTP packets.
• A system architect enables the system to support a
wide range of data types by applying various adapters,
which are developed through the API of Streaming
Data Platform software development kit, to the data-
transfer server.
3 Data-analysis server
• Streaming Data Platform is installed on the data-
analysis server.
• This server processes the stream data that is received
from a data-transfer server (based on a user-
developed analysis scenarios) to output the processed
stream data.
• The output formats that are supported include text
files, SNMP traps, and email.
• A data-analysis server is also able to send processed
stream data to other data-analysis servers and
dashboard servers. Therefore, a system architect can
build a scalable system by connecting multiple data-
analysis servers.
4 Dashboard server RTView of SL Corp. and HSDP are installed. HSDP inputs
stream data from the data analysis server and outputs to
the dashboard on the Viewer client of RTView. The user
can build a system that collects data from data sources
and analyzes in real time by HSDP and visualizes and
monitors the analysis results on the dashboard by RTView.
Hardware components 23
Hitachi Streaming Data Platform

Components of Streaming Data Platform and Streaming
Data Platform software development kit
The components of SDP systems are as follows: SDP servers, stream-data
processing engine, internal adapters, external adapters, SDP brokers, SDP
coordinators, SDP managers, custom data adapters, CQL debug tool, and
adapter library.
SDP and SDP SDK components in a development system
SDP components in a business system
24 Hardware components
Hitachi Streaming Data Platform

Description
The components and features of Streaming Data Platform and Streaming
Data Platform software development kit in SDP systems are as follows.
Table 2 Streaming Data Platform components and features
S.No.
Component Feature description
1 SDP server
• The SDP server receives, processes, and outputs
stream data.
• This server comprises the stream-data processing
engine and internal adapters, which are used to input
and output stream data.
2 Stream-data processing
engine
The stream-data processing engine processes stream data
based on analysis scenarios that are defined (through
CQL) by the user.
3 Internal adapter The internal adapters include the internal input adapter
and internal output adapter.
4 External adapter The external adapters include the external input adapter
and external output adapter.
Hardware components 25
Hitachi Streaming Data Platform

S.No. Component Feature description
5 SDP broker
• An SDP broker gets the I/O address of the stream data
from an SDP coordinator.
• This address is sent by the SDP broker to the SDP
servers and external adapters.
• The internal output adapters of the SDP servers and
external adapters connect to other SDP servers and
external adapters, based on the I/O address, to send
and receive stream data.
6 SDP coordinator
• An SDP coordinator manages the operation information
of the SDP servers such as I/O addresses for stream
data.
• The SDP coordinator can also form a cluster
(coordinator group) with the SDP coordinators of other
hosts.
• The cluster will be used to multiplex the operation
information of SDP servers.
7 SDP manager
• An SDP manager controls SDP servers, the SDP broker,
and SDP coordinator.
• If any SDP server fails, then the SDP manager can
recover the SDP servers based on the operation
information of the SDP servers.
8 Custom data adapter A custom data adapter receives processed stream data
from the internal output adapter of SDP servers and
outputs it to RTView.
Table 3 Streaming Data Platform software development kit components
and features
S.No.
Component Feature description
1 CQL debugging tool The CQL debugging tool debugs analysis
scenarios. The user operates the tool to test the
analysis scenarios developed by using CQL.
2 Adapter library The adapter library consists of the API modules
and headers of the external and internal
adapters. The user can use these utilities to
develop external and internal custom adapters.
SDP servers
An SDP server name is assigned as a unique identifier for each server that is
running in a working directory. Normally, SDP servers start with 1 and when
each server is added, it is incremented by 1.
26 Hardware components
Hitachi Streaming Data Platform

Description
The details of the server name are as follows:
• The rule for naming servers is N * N, where N is an integer whose value is
greater than or equal to 1 (a sequential unique number in a working
directory).
• If an SDP server is terminated normally, then its server name is released
and assigned to the next SDP server that starts.
• If an SDP server is restarted after an abnormal termination, then the
server name that was assigned earlier will be reassigned.
• Server names can be verified using the hsdpstatusshow command.
For more information about the options of the hsdpstatusshow command,
see Hitachi Streaming Data Platform Setup and Configuration Guide
Hardware components 27
Hitachi Streaming Data Platform

28 Hardware components
Hitachi Streaming Data Platform

3
Software components
This chapter provides information about the following components that are
used for processing streaming data: tuples, queries, query groups, windows,
and stream-data processing engine. Additionally, it provides information
about using CQL to process stream data, define streams and queries, and
using data-manipulation CQL to specify operations on stream data.
□
Components used in stream data processing
□
Using CQL to process stream data
□
Coordinator groups
□
SDP broker and SDP coordinator
□
SDP manager
Software components 29
Hitachi Streaming Data Platform

Components used in stream data processing
This section describes the components used in stream data processing.
The following figure shows the components used in stream data processing.
Figure 6 Components used in stream data processing
This section explains the following components shown in the figure.
1. Stream data : Large quantities of time-sequenced data that is
continuously generated.
2. Input and output stream queues : Parts of the stream data path.
3. Stream data processing engine : The part of the stream data processing
system that actually processes the stream data.
4. Tuple : A stream data element that consists of a combination of two or
more data values, one of which is a time (timestamp).
5. Query group : A summary analysis scenario used in stream data
processing. Different query groups are created for different operational
objectives.
6. Query : The action performed in stream data processing. Queries are
written in CQL.
7. Window : The target range of the stream data processing. The amount of
stream data that is included in the window is the process range. It is
defined in the query.
Stream data
Stream data refers to large quantities of time-sequenced data that is
continuously generated.
30 Software components
Hitachi Streaming Data Platform

Stream data flows based on the stream data type (STREAM) defined in CQL,
enters through the input stream queue, and is processed by the query. The
query's processing results are converted back to stream data, and then
passed to the output stream queue and output.
Input and output stream queues
The input stream queue is the path through which the input stream data is
received. The input stream queue is coded in the query using CQL statements
for reading streams.
The output stream queue is the path through which the processing results
(stream data) of the stream data processing engine are output. The output
stream queue is coded in the query using CQL statements for outputting
stream data.
The type of stream data that passes through the input stream queue is called
an input stream, and the type of stream data that passes through the output
stream queue is called an output stream.
Tuple
A tuple is a stream data element that consists of a combination of data
values and a time value (timestamp).
For example, for temperatures observed at observation sites 1 (ID: 1) and 2
(ID: 2), the following figure compares data items, which have only values,
with tuples, which combine both values and time.
Figure 7 Comparison of data items, which have only values, with tuples,
which combine both values and time
By setting a timestamp indicating the observation time to each tuple as
shown in the figure, data can be processed as stream data, rather than
handled simply as temperature information from each observation site.
There are two ways to set the tuple's timestamp: the server mode method,
where the timestamp is set based on the time the tuple arrives at the stream
Software components 31
Hitachi Streaming Data Platform

data processing engine, and the data source mode method, where the
timestamp is set at the time that the data was generated. Use the data
source mode when you want to process stream data sequentially based on
the time information in the data source, such as when you perform log
analysis.
The following subsections explain each mode.
Query
A query defines the processing that is performed on stream data. Queries are
written in a query definition file using CQL. For details about the query
definition file, see the Hitachi Streaming Data Platform Setup and
Configuration Guide.
Queries define the following three types of operations:
• Window operations, which retrieve the data to be analyzed from the
stream data
• Relation operations, which process the retrieved data
• Stream operations, which convert and output the processing results
• Stream to stream operations, which convert data from one data stream to
another
The following figures show the relationship between these operations.
Figure 8 Relationship between the operations defined by a query
32 Software components
Hitachi Streaming Data Platform

Figure 9 Stream to stream operation
A window operation retrieves stream data elements within a specific time
window. The data gathered in this process (tuple group) is called an input
relation.
A relation operation processes the data retrieved by the window operation.
The tuple group generated in this process is called an output relation.
A stream operation takes the data that was processed by the relation
operation, converts it to stream data and outputs it.
Stream to stream operations convert data from one data stream to
another by directly performing operations on the stream data without
creating a relation. In stream to stream operations, any processing can be
performed on the input stream data because there are no specific rules for
the data except that the input and output data must be stream data. To
perform processing, implement the processing logic for the stream to stream
function as a method in the class file created by a user with Java.
Interval calculations whereby data is calculated at fixed intervals (times) by
combining window operations, relational operations, and stream operations
used to be difficult. Now, interval calculations can be processed by using
stream to stream operations.
To use stream to stream operations, it is necessary to define the stream to
stream functions with CQL and create external definition functions. For details
on how to create external definition functions, see the Hitachi Streaming
Data Platform Application Development Guide.
For details about each of these operations, see
Using data manipulation CQL
to specify operations on stream data on page 35.
Stream data is processed according to the definitions in the query definition
file used by the stream data processing engine. For details about the
contents of a query definition file, see
Using CQL to process stream data on
page 35.
Software components 33
Hitachi Streaming Data Platform

Query group
A query group is a summary analysis scenario for stream data that has
already been created by the user. A query group consists of an input stream
queue (input stream), an output stream queue (output stream), and a query.
You create and load query groups to accomplish specific operations. You can
register multiple query groups.
Window
A window is a time range set for the purpose of summarizing and analyzing
stream data. It is defined in a query.
In order to summarize and analyze any data, you must clearly define a target
scope. With stream data as well, you must first decide on a fixed range, and
then process data in that range.
The following figure shows the relationship between stream data and the
window.
Figure 10 Relationship between stream data and the window
The stream data (tuples) in the range defined by the window shown in this
figure are temporarily stored in memory for processing.
A window defines the range of the stream data elements being processed,
which can be defined in terms such as time, number of tuples, and so on. For
details about specifying windows, see
Using data manipulation CQL to specify
operations on stream data on page 35.
Stream data processing engine
The stream data processing engine is the main component of Streaming Data
Platform and actually processes the stream data. The stream data processing
engine performs real-time processing of stream data sent from the input
adaptor, according to the definitions in a pre-loaded query. It then outputs
the processing results to the output adaptor.
34 Software components
Hitachi Streaming Data Platform

Using CQL to process stream data
Stream data is processed according to the instructions in the query definition
file used by the system. The query definition file uses CQL to describe the
stream data type (STREAM) and the queries. These CQL instructions are called
CQL statements.
There are two types of CQL statements used for writing query definition files:
• Definition CQL
These CQL statements are used to define streams and queries.
• Data manipulation CQL
These CQL statements are used to process the stream data.
This section describes how to use definition CQL to define streams and
queries, and how to use data manipulation CQL to perform processing on
stream data.
For additional details about CQL, see the Hitachi Streaming Data Platform
Application Development Guide.
CQL statements consist of keywords, which have preassigned meanings, and
items that you specify following a keyword. An item you specify, combined
with one or more keywords, is called a clause. The code fragments discussed
on the following pages are all clauses. For example, REGISTER STREAM
stream-name, consisting of the keywords REGISTER STREAM and the user-
specified item stream-name, is known as a REGISTER STREAM clause.
Using definition CQL to define streams and queries
CQL statements that are used to define streams and queries are called
definition CQL. There are two types of definition CQL.
• REGISTER STREAM clauses
• REGISTER QUERY clauses
The following subsections explain how to specify each of these clauses.
Using data manipulation CQL to specify operations on stream data
There are three types of data manipulation CQL operations:
• Window operations
• Relation operations
• Stream operations
• Stream to stream operations
Software components 35
Hitachi Streaming Data Platform

C External Definition Function
By using the External Definition Function in the C language, the external
definition stream to stream operation of the acceleration CQL engine can be
used.
To develop the C External Definition Function, you need to include the
headers that the library for the C EDF provides. The library for C EDF
provides structures and functions.
Coordinator groups
SDP coordinators can share information about the connection destinations of
query groups and streams across multiple hosts. SDP coordinators that share
such information are set in a coordinator group using the -chosts option of
the hsdpsetup command. For more details, see the Hitachi Streaming Data
Platform Setup and Configuration Guide. The SDP broker can find the streams
on all the hosts that use the same coordinator group by using the data that is
shared by a coordinator group. Therefore, external adapters and cascading
adapters can use the SDP broker on a host to connect to the streams that are
on multiple hosts. Additionally, if you set the SDP broker of a different host
that uses the same coordinator group as the connection destination, then the
same streams can be connected.
Coordinator group
Information multiplexing
36 Software components
Hitachi Streaming Data Platform

Description
A coordinator group that excludes the local host can be set. If the local host
is not specified in a coordinator group, then the SDP coordinator will not be
started. The SDP broker will use the SDP coordinator of another host to store
and find the information about the local host. In this case, the SDP broker,
which is available on the host that uses the same coordinator group, can
connect to the streams of the same host. Additionally, if the SDP broker uses
the SDP coordinator of another host, then a maximum of 1,024 SDP brokers
(including those that exist on the host of the reference destination SDP
coordinator) can connect to the coordinator group at the information
reference destination.
Coordinator group that does not include the local host
Software components 37
Hitachi Streaming Data Platform

You can set up data multiplicity by using the -cmulti option of the
hsdpsetup command.
When you configure a coordinator group that comprises three or more SDP
coordinators, multiple SDP coordinators can redundantly store identical
information. (You should set up data multiplicity by using the -cmulti option
of the hsdpsetup command. For more information, see the Setup and
Configuration guide.)
When data multiplicity is set to 2 or more, if the SDP coordinators fail within
a coordinator group because the number is less than the multiplicity that has
been set, then the SDP coordinators on another host can be used to continue
the operation. If the number of SDP coordinators that have failed is equal to
or greater than the multiplicity that has been set, then all the SDP
coordinators must be restarted. Additionally, if a query group was started and
running before the SDP coordinator failed, then the query group must be also
restarted.
If the coordinator group was running with two SDP coordinators, then you
can restore the coordinator group to the original state by restarting the
stopped SDP coordinators.
For more information, see Hitachi Streaming Data Platform Setup and
Configuration Guide.
38 Software components
Hitachi Streaming Data Platform

SDP broker and SDP coordinator
The SDP broker and SDP coordinator provide the functions that are used by
external adapters and cascading adapters to connect to the data-
transmission or reception-destination stream. A maximum of one SDP broker
and SDP coordinator can be run on a host. Additionally, you can use the
hsdp_broker operand in the SDP manager-definition file to specify whether
to start the process of the SDP broker. You can use the -chosts option of the
hsdpsetup command to specify whether to start the process of the SDP
coordinator. The SDP coordinator manages the locations of the SDP servers
where the streams are registered that can be connected on the host. The
SDP broker provides a function to search (from the SDP coordinator) for
information that is needed to locate the connection destination stream,
connect to it, and then pass the information to the external adapter and
cascading adapter. If a stream is re-registered to another SDP server later,
the SDP broker and SDP coordinator ensure that the operator can still run the
external adapters and cascading adapters by using the same settings.
Finding streams
Consolidating TCP ports
Software components 39
Hitachi Streaming Data Platform

Description
SDP brokers
An SDP broker obtains the I/O address of stream data from an SDP
coordinator and sends it to the SDP servers and external adapters. The
internal output adapters of the SDP servers and external adapters
connect other SDP servers and external adapters based on the address
information to send and receive stream data.
SDP brokers have the function to transfer connections through TCP
(communication established with external adapters or with cascading
adapters) to internal adapters, where data is sent to and received from
the streams on the local host.
By using this function, SDP brokers can relay connections between the
external adapters or cascading adapters and internal adapters, so that,
connections to different streams on the host can be received by using a
single port number.
40 Software components
Hitachi Streaming Data Platform

SDP coordinators
An SDP coordinator manages the operation information about the SDP
servers such as the I/O addresses of stream data. The SDP coordinator
can also form a cluster (coordinator group) with the SDP coordinators of
other hosts to multiplex the operation information of the SDP servers.
Information managed by the SDP coordinator
The query group that is registered to the SDP server is started by the
SDP broker. When the query group is deleted from the SDP server, the
corresponding registration information is deleted from the SDP broker.
When any information is registered or deleted, if a coordinator group is
set up, then the current registration information is shared immediately
by all SDP coordinators in the coordinator group. The information that is
registered to the SDP coordinator is as follows.
Table 4 Information managed by the SDP coordinator
#
Item Description
1 Host Host name or IP address of the HSDP
system where the connection destination
stream is registered
2 HSDP-working-directory Absolute path of the working directory of
the SDP server where the connection
destination stream is registered
3 Server cluster name Name of the server cluster to which the
server belongs
4 Server name Name of the SDP server
5 Query group name Name of the query group where the
connection destination stream is defined
6 Stream name Name of the connection destination stream
7 TCP connection port TCP port
8 RMI connection port RMI port
9 Stream type Stream type: Input/output
10 Timestamp mode Time stamp mode of the connection
destination stream
11 Dispatch type Property information that describes the
method for dispatching data to the
connection destination stream
12 Schema information Schema information of the connection
destination stream
SDP manager
An SDP manager controls SDP servers, an SDP broker, and an SDP
coordinator.
Software components 41
Hitachi Streaming Data Platform

Description
When an SDP server fails, the SDP manager recovers the SDP server based
on the operation information (of the SDP server) that is retained by the SDP
coordinator.
Log notifications
The log notification feature of the SDP manager is used to monitor the
processes of the various components that are available in a host. When a
process shutdown is detected, the log notification feature outputs messages
to log files.
Process monitoring
Description
The log notification feature monitors the performance of the following
components (in a host):
• SDP broker
• SDP coordinator
• SDP servers
A maximum of one SDP manager can run on a host.
42 Software components
Hitachi Streaming Data Platform

The processes of the SDP broker, SDP coordinator and SDP server
components can be started by running the hsdpmanager or hsdpstart
command.
The processes of the components are activated when the processes are
started. When the processes of the components are activated, the SDP
manager starts monitoring these processes. While monitoring , if a process
shuts down because of a failure, then the SDP manager detects the shutdown
and outputs a message to the log files of the SDP manager. The message
comprises the details about the failure and subsequent shutdown. For more
information about the log files of SDP manager, see Hitachi Streaming Data
Platform Setup and Configuration Guide.
The SDP manager does not monitor the processes of any of the components
if either of the following conditions is met:
• If the SDP manager has not been started by running the hsdpmanager
command.
• If a component has not been started by running the hsdpmanager or
hsdpstart command and the hsdpcql command.
Restart feature
The restart feature of the SDP manager provides the functionality to monitor
the processes of each component that is displayed in log notifications and
restart any processes that have shut down.
Description
When the SDP server is restarted, the query groups and internal adapters
(running on the server before the server shut down) are also restarted.
Additionally, the SDP manager also restarts its own processes that have shut
down. You can enable or disable the restart feature in the hsdp_restart
property of the SDP manager-definition file. For more information about the
SDP manager-definition file, see Hitachi Streaming Data Platform Setup and
Configuration Guide. The CPU, which is specified for the hsdp_cpu_no_list
property of the SDP manager-definition file, is assigned to the process of the
component that has been restarted.
The SDP manager does not restart the processes of a specific component if
any of the following conditions are met:
• If the SDP manager has not been started by running the hsdpmanager
command, then it does not restart any of the processes (including its own
processes) of any of the components.
• If a component has not been started by running the hsdpmanager or
hsdpstart command and the hsdpcql command, then the SDP manager
does not restart the processes of any of the components.
Software components 43
Hitachi Streaming Data Platform

• If the restart setting has been disabled, then the SDP manager does not
restart any of the processes (including its own processes) that are
displayed in the log notifications.
• If a specific operating system is specified as a prerequisite, then based on
the type of operating system, the SDP manager does not restart any of its
own components even if restart has been enabled.
Table 5 Availability of the restart feature of the SDP manager
Prerequisite operating system Versions
SDP manager can be
restarted
Red Hat Enterprise Linux 6.5 Yes
Red Hat Enterprise Linux Advanced Platform 6.6 Yes
7.1 Yes
SUSE Linux Enterprise Server 11 SP2 No
11 SP3 No
12 Yes
Note: When a process is shut down, if the restart feature is unavailable, then
the user must manually restart the process of the SDP manager by using the
hsdpmanager command.
While a component is restarting, if an inter-process connection fails, then the
SDP manager tries a restart request again. You can specify the number of
retries and the corresponding wait intervals in the hsdp_retry_times and
hsdp_retry_interval properties (of the SDP manager-definition file)
respectively. For more information about SDP manager-definition file, see
Hitachi Streaming Data Platform Setup and Configuration Guide. If a
shutdown process fails to restart even after the restart request has been run
for the specified number of times, then the SDP manager stops attempting to
restart the component and starts monitoring other components.
If the SDP coordinators meet both the following conditions, then the SDP
coordinators cannot be restarted by the SDP manager:
• Coordinator group comprises of three or more SDP coordinators
• Number of SDP coordinators equal to or greater than the specified
multiplicity have stopped
If the SDP coordinators cannot be restarted, then all the SDP coordinators
that are running within the coordinator group should be stopped by using the
hsdpmanager -stop command. After stopping all the SDP coordinators, they
have to be manually restarted by running the hsdpmanager -start
command. In this case, if a query group is running, then the stream
44 Software components
Hitachi Streaming Data Platform

information registered to the SDP coordinators is lost. Therefore, the query
group should be restarted.
Software components 45
Hitachi Streaming Data Platform

46 Software components
Hitachi Streaming Data Platform


Filtering records
To perform stream data processing only on specific records, you use a filter
as the data editing callback.
For example, if you are monitoring temperatures from a number of
observation sites and you want to summarize and analyze temperatures from
only one particular observation site, you can filter on that observation site's
ID.
Only common records can be filtered. If the input source is a file, after an
input record is extracted by the file input connector, you must use the format
conversion callback to convert it to a common record before filtering it.
When specifying the evaluation conditions you want to filter on, you can use
any of the record formats and values that are defined in the records. The
following figure shows the positioning and processing of the callback involved
in record filtering.
48 Data processing
Hitachi Streaming Data Platform

Figure 11 Positioning and processing of the callback involved in record
filtering
1. The records passed to the filter are first filtered by record format.
Only records of record format R1 meet the first condition, so only these
records are selected for processing by the next condition. Records that
do not satisfy this condition are passed to the next callback.
2. After the records are filtered by record format, they are then filtered by
record value.
This condition specifies that only those records whose ID has a value of 1
are to be passed to the next callback. In this way, only those records
that satisfy both conditions will be processed by the next callback.
Records that do not satisfy these conditions are discarded.
Data processing 49
Hitachi Streaming Data Platform

Extracting records
After you have filtered for the desired records, you use a record extraction
callback to collect all of the necessary information from the filtered records
into a single record.
For example, to summarize and analyze the responsiveness between a client
and a server, after the HTTP packet input connector is used as the input
callback, you could use a record extraction callback as the data editing
callback. You could then use the record extraction callback to join an HTTP
request and response packet pair into one record, based on the transmission
source IP addresses and the transmission destination IP addresses. This
would allow you to gain a clear understanding of response times, and to
easily summarize and analyze the resulting data.
In the following figure, after records are filtered by record format and record
value so that only the desired records are selected, the record extraction
callback joins the resulting records, and generates a new record. The
following figure shows the positioning and processing of the callback involved
in record extraction.
50 Data processing
Hitachi Streaming Data Platform
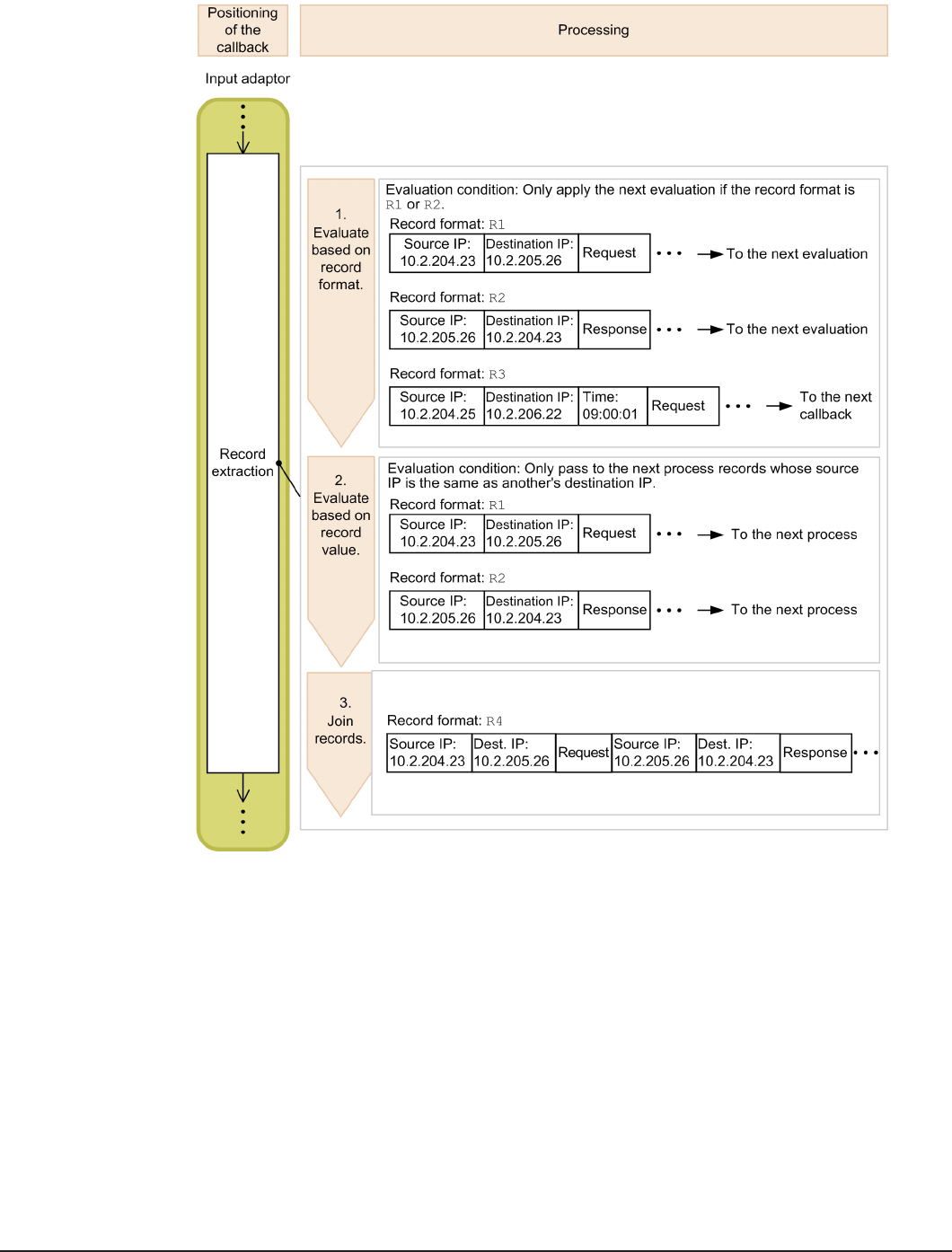
Figure 12 Positioning and processing of the callback involved in record
extraction
1. Records passed to the record extraction callback are first filtered by
record format.
Only records whose record format is R1 or R2 meet the first condition, so
only these records are selected for processing by the next condition.
Records that do not satisfy this condition are passed to the next callback.
2. After the records are filtered by record format, they are then filtered by
record value.
Data processing 51
Hitachi Streaming Data Platform

This condition specifies that records are to be passed to the next process
only if the source IP of the request matches the destination IP of the
response, and the destination IP of the request matches the source IP of
the response. This means that only those records that match this
condition are passed to the next process.
3. Records filtered by record format and record value are joined to produce
a single record.
Records joined in this step are selected for processing by the next
callback.
52 Data processing
Hitachi Streaming Data Platform

5
Internal adapters
This chapter provides information about internal adapters. The internal
adapters provided with SDP are also called internal standard adapters. The
two types of internal adapters are as follows: internal input adapters and
internal output adapters. User-developed internal adapters, also called
internal custom adapters, can be developed by using the Streaming Data
Platform software development kit APIs.
□
Internal input adapters
□
TCP data input adaptor
□
Inputting files
□
Inputting HTTP packets
□
Outputting to the dashboard
□
Cascading adaptor
□
Internal output adapters
□
SNMP adaptor
□
SMTP adaptor
□
Distributed send connector
□
Auto-generated adapters
Internal adapters 53
Hitachi Streaming Data Platform

Internal input adapters
Internal input adapters receive stream data in specific formats and send the
data to the stream-data processing engine.
Description
The formats that are supported by the internal input adapters are as follows:
• Text files
• HTTP packets
TCP data input adaptor
Overview of the TCP data input adaptor
Streaming Data Platform provides TCP-data input adapters for one of the
internal standard adapters. When a user program or cascading adapter sends
a connection request for data transmission to Streaming Data Platform, a
TCP-data input adapter receives a connection notification through the SDP
broker. The TCP-data input adapter receives data from the source program
through an established TCP connection. It converts the TCP data that has
been received into tuples and sends the tuples to the SDP servers. The TCP-
data input adapter receives data from the connection source through an
established TCP connection. It converts the TCP data, which has been
received, into tuples and sends the tuples to the SDP server.
54 Internal adapters
Hitachi Streaming Data Platform

Figure 13 Receive TCP data and send tuples
TCP data input adaptor: Sends the tuples to a Java stream in the SDP server.
Prerequisites for using the TCP input adaptor
The following are prerequisites for using this adaptor.
Input adaptor configuration of the TCP data input adaptor
The TCP data input connector must be set as an input connector of input
adaptor. The following figure and list shows the combination of callbacks in
the input data adaptor configuration. If the TCP data is sent by using an
external input adapter as a program, then the SDP broker must be running
on a host that is using a TCP-data input adapter. If you use an external input
adapter as the transmission source of TCP data, then the SDP broker must be
running on the host on which you want to use the TCP-data input adapter.
When a connection request is received from the external input adapter, the
SDP broker starts the TCP input adapter, which is required for
communication.
Internal adapters 55
Hitachi Streaming Data Platform

Figure 14 Input adaptor configuration
Table 6 List of the callback combinations
Adaptor
Type
Callback combination
Input Callback Editing Callback Sending Callback
Java TCP data input
connector
Any kind of editing
callback can be set or
omitted
Any kind of sending
callback
C - Sending callback
User program that acts as data senders
User programs that send data to the TCP data input adaptor for C must be
implemented with the external-adapter library. When the external-adapter
library is used to implement a TCP-data input adapter, the user program
specifies both the stream information and address of the SDP broker for the
host (running in the TCP input adapter) in the definition file of the external
input adapter. This enables the external input adapter to establish
communication.
TCP data input connector
This section describes details of the TCP data input connector that is
processing of the input adaptor.
Number of connections
After the TCP-data input adapter has been started, the TCP-data input
connector receives data from the data source through a TCP connection.. The
following table shows the number of connections that are established
between the user program and this adaptor for Java.
56 Internal adapters
Hitachi Streaming Data Platform

Table 7 Number of connections
Adaptor type Number of connections Output tuples
Java 1 to 16 connections (per adaptor) can
be established as indicated in
Figure 15 Number of connections (for
Java) on page 57.
Tuples that are sent to the Java
stream in the HSDP server by this
adaptor are time-sequenced data.
Figure 15 Number of connections (for Java)
TCP data format
This connector input TCP data as follows:
Figure 16 TCP data format
As shown above, TCP data consists of header data and a series of one or
more units of data. Each unit of data consists of a given number of data
items. This connector processes header data and units of data as follows:
Internal adapters 57
Hitachi Streaming Data Platform

Figure 17 Form unit data into record
The sections shown in the above figure are as follows:
1. Seek the byte size of the header data as an offset.
2. Seek the byte size of the fixed-length data as an offset.
3. Seek the byte size of the data as an offset.
4. Form the data into a record field.
5. Repeat section 3 and 4.
6. When the connector has performed the seek to the end of the unit of
data, the connector outputs the record to the next callback.
7. Repeat section 2 to 6.
The user defines each byte size of the offset and data of the target to be
formed in the adaptor composition file, and can select the data to be formed
into record fields. The details of header information are as follows.
Item
Description Size Data type
Data kind Specifies the kind of data.
0: Normal data
2 bytes
short
(Reserved) A domain reserved for future
extension.
2 bytes
short
If the TCP data input connector inputs data whose data type is variable-
length character (VARCHAR) and then forms input data into a record field, the
58 Internal adapters
Hitachi Streaming Data Platform

user program that acts as data senders has to send the data to the TCP data
input connector with the following data format:
Figure 18 Data format of the TCP data input connector
Table 8 Description of the data format
Item
Description Size Data type Value
Data length Specifies the
length of the byte
array that stores
variable-length
character data.
If this value is
more than the
size attribute
value of the TCP
data input
connector
definition in the
adaptor
configuration
definition file, the
TCP data input
connector outputs
the KFSP48916
warning message,
inputs the
variable-length
character data
from the
beginning to the
size attribute
value, and then
2
bytes
short
An integer from 0
to 32767
Internal adapters 59
Hitachi Streaming Data Platform

Item Description Size Data type Value
forms input data
into a record field.
If a value of zero
is specified, the
variable-length
character data
must be omitted.
In this case, the
TCP data input
connector forms a
null character into
a record field.
Variable-length
character data
Specifies the byte
array that stores
variable-length
character data.
The length of the
byte array must
be same as the
value specified in
the data length.
Note that the TCP
data input
connector does
not check the
value of this data
(for example, the
character code
and control
characters), and
then forms the
specified byte
array into a record
field without any
changes.
1 to 32767 bytes
varchar
Any characters
Byte order of data
This connector forms data into the record fields according to the big-endian
byte order.
Restart reception of TCP connection
When a user program closes the TCP connection, this connector restarts
reception of TCP connections and the input adaptor continues processing. If
the user program closes the TCP connection while sending TCP data, this
connector deletes the TCP data that this connector is receiving, and restarts
reception of TCP connections.
Setting for using the TCP data input adaptor
When starting a TCP-data input adapter, you do not require an adapter-
definition file to work with the SDP broker. However, for SDP servers that
60 Internal adapters
Hitachi Streaming Data Platform

connect with the SDP broker and run in a scale-up or scale-out configuration,
you need to define (in the query-group properties file) how to distribute data
from the adapter to the input streams. If the TCP-data input adapter waits
for data at a certain port number, the user must determine the connector
settings by specifying the TCP data input connector definition in the adaptor
composition file. For more information, see TCP data input connector
definition section in the Hitachi Streaming Data Platform Setup and
Configuration Guide.
Comparison of supported functions
The following is a comparison list of supported functions between Java and C.
Table 9 Comparison list of supported functions
Function
Supported
Large classification Middle classification Small classification Java adaptor
Fixed length data types BYTE - Yes
SHORT - Yes
INT - Yes
LONG - Yes
FLOAT - Yes
DOUBLE - Yes
BIG_DECIMAL - No
CHAR ASCII Yes
Multi-byte character No
DATE - No
TIME - No
TIMESTAMP - Yes
Variable length data type VARCHAR ASCII Yes
Multi-byte character No
Data format Fixed length data - Yes
Variable length data - No
Data offset setting
1
- - Yes
Zero extension - - Yes
Record format Single record - Yes
Multiple record - No
Connection control
(between TCP data sender and
adaptor)
Single connection - Yes
Multi connection - No
SDP broker connections Integration of TCP
connections
- Yes
Type check Adaptor-input stream - No
Internal adapters 61
Hitachi Streaming Data Platform

Function Supported
Large classification Middle classification Small classification Java adaptor
Connectivity of adaptor with TCP
data sender
TCP cascading adaptor - Yes
C TCP cascading
adaptor
- Yes
External input adapter - Yes
Inputting files
To perform stream data processing on data files, such as log files, you use
the file input connector as the input callback.
The file input connector extracts records to be processed from an input
source file. Because these records are retrieved as input records, the format
conversion callback must be used to convert them to common records so that
the stream data processing engine can process them. The following figure
shows the positioning and processing of the callbacks involved in file input.
Figure 19 Positioning and processing of the callbacks involved in file input
1. The file input connector extracts the first line (record) from the input file.
The record that it extracts is called an input record.
62 Internal adapters
Hitachi Streaming Data Platform

2. The format conversion callback converts the input record to a common
record.
Tip: You can also extract and process multiple records at a time from the
input source file.
Inputting HTTP packets
To perform stream data processing on HTTP packets carried over a network,
you use the HTTP packet input connector as the input callback.
This packet input connector extracts HTTP packets from the output of a
packet analyzer. The following figure shows the positioning and processing of
the callback involved in HTTP packet input.
Figure 20 Positioning and processing of the callback involved in HTTP
packet input
As shown in the figure, the packet input connector extracts the HTTP packet,
and then converts it to a common record data format that the stream data
processing engine can handle.
Outputting to the dashboard
To display the results of stream data processing to the dashboard, you use
the dashboard output connector as the output callback. Data output to the
dashboard can be displayed as a line chart, a bar chart, or in other chart
formats.
Internal adapters 63
Hitachi Streaming Data Platform

The dashboard output connector gets common records from the previous
callback. The dashboard output connector then converts these records to
data that can be displayed on the dashboard. The following figure shows the
positioning and processing of the callback involved in dashboard output.
Figure 21 Positioning and processing of the callback involved in
dashboard output
Cascading adaptor
Streaming Data Platform provides cascading adapters for one of the internal
standard adapters. The cascading adapters send data (analysis results) from
Streaming Data Platform to the destination SDP server or external output
adapter through TCP sockets. Cascading adapters are generated
automatically to use while transmitting data internally. You cannot use your
internal adapters for the internal-data transmission process.
64 Internal adapters
Hitachi Streaming Data Platform

Figure 22 Example of a connection for the cascading adaptor
Data transmission to an SDP server
The figure illustrates the configuration of a cascading adapter that
connects host A to an SDP server in host B. The adapter transmits data
from the output stream of host A to the input stream of host B. The
information about the connected input/output streams is defined in the
query-group properties files for host A. Information about the connected
stream is defined so that the adapter starts (automatically) at the same
time as the query group. After starting, the adapter inquires and gets
the address of the stream that is connecting to the SDP broker of host A
and then establishes a connection through the SDP broker of host B. The
method of distributing the input stream data of host B must be defined
in the query-group definition file of host B.
Data transmission to external output adapters
The figure illustrates the configuration of a cascading adapter that
connects to an external output adapter. When the external output
adapter requests a TCP connection, the broker starts the cascading
adapter. After starting, the cascading adapter uses the established
connection to send data to the external output adapter.
In this configuration, you can omit creation of the adapter configuration
definition file. In addition, if you want to change the action of the
connection-retry method from the default action, follow the procedure
described in Release note.
Internal adapters 65
Hitachi Streaming Data Platform

Figure 23 Example of a connection for the cascading adaptor 2
Cascading adaptor processing overview
A cascading adaptor consists of the following callbacks.
Figure 24 Cascading adaptor configuration
Callbacks
Receive tuple
This callback receives tuples from an HSDP server.
Edit data
This callback changes the format of the received data. This callback can
be omitted.
RMIClient
66 Internal adapters
Hitachi Streaming Data Platform

This callback inputs a tuple into the stream of an HSDP server of Host B
using RMI communication.
TcpClient
This callback inputs a tuple into the stream of an HSDP server of Host B
using TCP socket. If the socket option TCP_NODELAY is enabled, data is
sent immediately.
Output adaptor configuration
The following table lists the combination of callbacks in the configuration of
the output data adaptor.
Table 10 List of the callback combinations
Adaptor Type
Callback combination
Receiving Callback Editing Callback Output Callback
Java Any kind of receiving
callback
Any kind of editing
callback can be set or
omitted
Cascading callback
(RMI / TCP client)
Communication method
When using the cascading adaptor, the communication method between the
frontend and backend servers has to be chosen from among Java RMI and
TCP socket. The operator needs to specify the selected method in the
cascading properties file.
The two types of methods have different features as shown in the following
table.
Table 11 Using Java RMI or TCP socket
Item
Using Java RMI Using TCP socket
Connectivity * The adaptor can connect to the
Stream engine in the SDP server.
The adaptor can connect to the TCP
data input adaptor for Java/C that is
running on the stream engine in the
HSDP server.
Available data
types inside a
tuple being sent
All data types listed in Table 12 Using
Java RMI or TCP socket on page 68
are available.
For details on data types, see the
Hitachi Streaming Data Platform
Setup and Configuration Guide.
The available data types are listed in
Table 12 Using Java RMI or TCP socket
on page 68.
For details on data types, see the
Hitachi Streaming Data Platform Setup
and Configuration Guide
TCP port Destination port
The adaptor uses the following two
types of TCP ports:
Destination port
The adaptor uses the standby port
number of the SDP broker in the
destination host.
Internal adapters 67
Hitachi Streaming Data Platform

Item Using Java RMI Using TCP socket
• The port number defined in the
cascading properties file.
• An ephemeral port, where a
number is assigned to each
destination randomly.
Source port
The adaptor uses TCP ports that are
randomly assigned for each
destination.
Source port
The adaptor uses TCP ports that are
randomly assigned for each
destination.
* For details, see Table 15 Connection details for cascading adaptors on page 73.
Table 12 Using Java RMI or TCP socket
Data type
Java RMI TCP socket Remarks
INT Y Y -
SHORT Y Y -
BYTE Y Y -
LONG Y Y -
BIG_DECIMAL Y N -
FLOAT Y Y -
DOUBLE Y Y -
STRING Y Y Before sending data, the Java cascading adaptor
with TCP socket converts STRING data into a
byte array of the specific character encoding
specified in the cascading client connector
definition. If STRING data cannot be converted
into a byte array of specified encoding, the
adaptor discards a tuple.
DATE Y N -
TIME Y N -
TIMESTAMP Y Y -
Legend:
• Y: Available data type
• N: Unavailable data type
Features
Cascading adaptors can connect to multiple HSDP servers as destinations.
When multiple HSDP servers connect with a cascading adaptor, the adaptor
decides the destination based on the dispatch type that is specified in the
adaptor definition file. For more information about definition file formats, see
Cascading section in the Hitachi Streaming Data Platform Setup and
Configuration Guide.
68 Internal adapters
Hitachi Streaming Data Platform

The available dispatch types are described below. Only one of them can be
used.
Table 13 Dispatch types
Dispatch type Description Figure
Hashing A destination of each type of data is determined
by the hash value of column data in a tuple.
Figure 25 Hashin
g overview on
page 69
Round-robin Data is distributed to the HSDP servers by
round-robin
Figure 26 Round-
robin overview on
page 70
Static rule A destination for each type of data is determined
by the user defined static rule. This rule can be
specified for each column value in a tuple. For
example, if the tuple has an "ID" column, you
can specify it so that data with ID="port1" is
sent to HSDP server1, and data with ID="port2"
is sent to HSDP server2. If a tuple does not
match any static rule, the adaptor discards that
tuple and outputs a message to a log file.
Figure 27 Static
rule overview on
page 70
All Equivalent data has to be sent to all the
destination SDP servers.
Figure 28 All
overview on
page 70
Hashing
Figure 25 Hashing overview
Round-robin
Internal adapters 69
Hitachi Streaming Data Platform

Figure 26 Round-robin overview
Static rule
Figure 27 Static rule overview
Hashing
Figure 28 All overview
The features of cascading adaptors are as follows:
• The cascading adapters that connect to the input stream of another SDP
server can start automatically when the query group starts. If you define
the information on the source and destination streams in the query-group
properties file, then the cascading adapters will start automatically when
the query group starts.
• The cascading adapter, that connects to an external output adapter starts
automatically when the external output adapter requests a connection.
70 Internal adapters
Hitachi Streaming Data Platform

• Cascading adaptors connect to the host defined in the cascading properties
file using an RMI connection. The path of that file is defined in the adaptor
composition file.
• When an SDP server is connected to a data-parallel configuration, the data
is sent by the cascading adapter based on the distribution method (used in
the query-group definition file of the destination SDP server). The
distribution method in the adapter-definition file is defined by using an RMI
connection.
(In an RMI connection, define the distribution method in the adapter-
definition file.
For more information about the formats of the definition file, see the
Hitachi Streaming Data Platform Setup and Configuration Guide.
• Host-to-host communication between a cascading adaptor and an HSDP
server is possible.
• When you want to connect a cascading adapter with an SDP sever to send
data, the destination SDP server should be started before you start the
query group that runs the adapter.
• If an error in connection occurs while transmitting the data, then the
cascading adapter tries to transmit the data again.
For cascading adapters that connect to an SDP server:
If an adapter is disconnected from the input stream of the destination SDP
server, then the cascading adapter tries to connect again. You can specify
the number of retries, the retry interval, and whether to send the
remaining data (in a query-group properties file) after reconnection. When
the number of failures exceed the number of retries, the process to send
data to the connection destination stream (where the error occurred) is
stopped.
For cascading adapters that connect to an external output adapter:
If an adapter is disconnected from the external output adapter, then the
external output adapter tries to connect again. You can specify the wait
time for each retry (in an adapter-definition file). If the connection is not
re-established after the wait time for retrying the connection has lapsed,
then the process that waits for a reconnection by the external adapter is
stopped.
• If a dispatch type is either HASHING or STATIC rule, the destination of
dispatched data is fixed. Even if a cascading adaptor cannot send data to a
destination because of a communication error, the destination of the
dispatched data does not change.
• If the number of pending tuples exceeds the internal queue size in the
cascading adaptor, the oldest pending tuple will be removed from the
queue.
Internal adapters 71
Hitachi Streaming Data Platform

• When a custom developer uses multiple cascading adaptors and wants to
send data to the same input stream of an HSDP server, data must be
sorted by timestamps. The following are two configurations that can be
used to send data to the same input stream.
Table 14 Configurations of multiple cascading adaptors
Configuration
Description
Figure 29 Example 1 on
page 72
Multiple output streams connect to a single input stream
This configuration is effective when a latency delay is allowed.
When analyzing time series data, input tuples must be sorted by
timestamp in the backend server.
Figure 30 Example 2 on
page 73
Multiple output streams connect to multiple input streams.
The numbers of output and input streams are equal.
This configuration is effective when a latency delay is not allowed.
When analyzing time series data, input tuples are sorted by
timestamp when the UNION query is executed in HSDP server 2.
If one of the streams stops, the HSDP server 2 in the figure will stop.
When HSDP server 2 is the acceleration engine, this configuration
cannot be used.
Figure 29 Example 1
When a HSDP server 1 is the acceleration engine, TCP data input adaptors for
C needs to be added to the figure.
72 Internal adapters
Hitachi Streaming Data Platform

Figure 30 Example 2
To send data through a firewall, the person who deploys the HSDP servers
should open the source and destination ports in the firewall settings. For
details about using ports, see
Table 11 Using Java RMI or TCP socket on
page 67.
Connection details
The following table shows connection details for cascading adaptor.
Table 15 Connection details for cascading adaptors
Item
Cascading adaptor
Java
RMI
TCP
(Java)
TCP
(C)
Destination to connect
to
Standard adaptor TCP data input adaptor
(for Java)
N Y Y
TCP data input adaptor
(for C)
N Y Y
CQL engine Stream engine
(Java Engine)
Y N N
Acceleration CQL
engine
N N N
Legend:
• Y: Can be connected
• N: Cannot be connected
Time synchronization settings
You can use the time synchronization feature of the cascading adaptor or you
can define and control synchronization on your own. When you choose to use
the synchronization function of the system, HSDP achieves stream data
Internal adapters 73
Hitachi Streaming Data Platform

processing by continuously processing time-series data in real-time as the
data is created. As a result, stream data processing is generally based on a
unique time axis. When you construct a query by connecting multiple stream
engines, the cascading adaptor performs time synchronization among those
engines. The following table describes the time synchronization function of
the cascading adaptor.
Table 16 Time synchronization function of the cascading adaptor
Function
Description
Time synchronization of
analysis*
The cascading adaptor sets an analysis time for the system time field
of the tuple (the systemTime field of the StreamTuple class) and
passes the tuple to the destination stream engine.
The timestamp mode of the destination stream engine must be set
to data source mode for the destination stream engine to use the
time.
Heartbeat The cascading adaptor periodically sends a heartbeat to synchronize
the time for the destination stream engines.
Figure 31 System composition on page 74 and Table 17 Setting details on
page 74 provide examples of using the time synchronization function of the
cascading adaptor.
Figure 31 System composition
Table 17 Setting details
Server
Component Setting Description
HSDP server 1 Stream
engine
Set the one of the following:
stream.timestampMode=Server
stream.timestampMode=DataSo
urce
1
You can specify either
timestamp mode.
CQL Register a query based on time
control of the stream engine.
-
Cascading
heartbeat=ON
2
The cascading adaptor
synchronizes the time of the
74 Internal adapters
Hitachi Streaming Data Platform

Server Component Setting Description
Adaptor HSDP servers by sending a
heartbeat.
HSDP server 2 Stream engine
stream.timestampMode=DataSo
urce
1
HSDP server 2 must set to the
data source mode.
stream.timestampPosition =
__systemtime__
1
By setting __systemtime__ for
the input stream to which the
cascading adaptor connects,
you can specify for HSDP server
2 to use the system time of
tuple.
CQL Register a query based on time
control of the stream engine.
-
For more information about the settings for the cascading adapters, see System configuration
property file (system_config.properties) section in the Hitachi Streaming Data Platform Setup and
Configuration Guide.
Instead of using the time synchronization, you can control time
synchronization by using the external definition function. To do this, the user
must turn off the time synchronization. The following figure and table show
how to use the external definition function to control time synchronization.
Figure 32 System composition
Table 18 Setting details
Server
Component Setting Description
HSDP server 1 Stream Set the one of the following: You can specify either
timestamp mode.
Internal adapters 75
Hitachi Streaming Data Platform

Server Component Setting Description
engine
stream.timestampMode=Server
stream.timestampMode=DataSo
urce
1
CQL Register a query that has the
timestamp column in the
schema of the output stream
and that outputs the tuple
created by the external
definition function.
-
Cascading
Adaptor
heartbeat=OFF
2
Because the cascading adaptor
is not used to synchronize the
time, turn off the function for
sending heartbeats.
External
definition
function
Make an external definition
function that does the following:
• Controls time
synchronization and sets the
time for the tuple it creates.
• Periodically creates a
heartbeat tuple (If the
cascading adaptor is
connected to multiple
stream engines, the external
definition function must
send a heartbeat tuple to
each stream engine.).
-
HSDP server 2 Stream engine
stream.timestampMode=DataSo
urce
1
HSDP server 2 must be set to
the data source mode.
stream.timestampPosition =
column-name
1
The user must specify the name
of the time-data column for the
input tuple so that the stream
engine uses the time of the
tuple created by the external
definition function.
CQL Specify the timestamp column
for the schema of the input
stream.
-
Notes:
1. For more information, see the Hitachi Streaming Data Platform Setup and Configuration
Guide.
2. For details about the settings for the cascading adapor, see the manual Hitachi Streaming
Data Platform Setup and Configuration Guide.
Internal output adapters
Internal output adapters receive processed stream data from a stream-data
processing engine and output the data in a specific format.
The formats supported by the internal output adapters are as follows:
76 Internal adapters
Hitachi Streaming Data Platform

• Text files
• SNMP traps
Internal output adapters can output the processed stream data to internal
input adapters, internal output adapters, and custom data adapters.
SNMP adaptor
The Simple Network Management Protocol (SNMP) is a protocol to monitor
and manage networks using UDP. The SNMP versions are listed below and
HSDP supports SNMP v1 and v2c:
• SNMP v1: RFC1155-1157
• SNMP v2c: RFC1901-1908
SMTP adaptor
HSDP provides an email-sending feature, in which an SMTP adaptor receives
a tuple as an event from an HSDP server, and then sends the event via email
by using Simple Mail Transfer Protocol (SMTP).
Distributed send connector
This section describes detail about distributed send connector that is
processing of this adaptor.
Auto-generated adapters
Internal standard adapters are generated, started, or stopped automatically
by using a function that is provided with HSDP. While communicating with
this function by using an external adapter, you need not create an adapter-
definition file or in-process connection properties file. Additionally, you need
not use commands to start and stop an adapter.
Generation of adapters
When a query group is registered, the following adapters are generated
automatically:
• TCP input adapter (for connecting the external input adapter)
• Cascading adapter (for connecting the external output adapter)
• Cascading adapter (for connecting the TCP input adapter)
Internal adapters 77
Hitachi Streaming Data Platform

Starting of adapters
The internal standard adapters are started automatically in the following
cases:
• An internal or external adapter requests a connection to an input or output
stream.
• The query group is started.
Based on the type of configuration, the adapters are started as follows:
Scale-out configuration
In a scale-out configuration, when a connection is requested from an
external adapter, the internal adapter is automatically started in each of
the working directories that have been scaled out. When a query group
is started, the adapter is automatically started only in the working
directory in which the hsdpcqlstart command was run.
Scale-up configuration
In a scale-up configuration, when an adapter (auto-generated) is started
automatically, the same number of adapters (equal to the number of
scaled-up query groups) are started. This means that one adapter group
is started with the predefined number of adapters.
TCP input adapter (for connecting the external input adapter)
The TCP input adapter receives data and puts it into the stream-data
processing engine through the input stream. When a connection is
requested by an external input adapter or a cascading adapter, if the
SDP broker is started and running, then the TCP input adapter is
automatically started.
The details of the TCP input adapter are as follows:
• Name of the adapter group to be started
tcpinput-query-group-name-input-stream-name-to-connect
The value in query-group-name indicates the name of the query group
that defines the stream that should be connected.
• Name of the adapter
tcpinput[-N]
The number -N is only added for a scale-out configuration. The value of N
is one or more (three-digit decimal number, that is, the scale-up number,
such as 001, 002, and so on).
Cascading adapter (for connecting the external output adapter)
78 Internal adapters
Hitachi Streaming Data Platform

The cascading adapter gets data from the stream-data processing
engine and sends it through the output stream. When a connection is
requested by an external output adapter, if the SDP broker is started
and running, then the cascading adapter is started automatically.
The details of the cascading adapter are as follows:
• Name of the adapter group to be started
cascading-out-query-group-name-output-stream-name-to-connect
The value in query-group-name indicates the name of the query group
that defines the stream that should be connected.
• Name of the adapter
cascading[-N]
The number -N is only added for a scale-up configuration. The value of N is
one or more (three-digit decimal number, that is, the scale-up number,
such as 001, 002, and so on).
Cascading adapter (for connecting the TCP input adapter)
The cascading adapter gets data from the output stream and sends it to
the connection destination input stream. When the query group starts,
the cascading adapter that sends data to the input stream
*
of the
connection destination that is specified in the properties file (of the
query group) is started.
Legend: * Refers to the input stream that is specified as the value of the
stream.output.stream-name.link property.
The details of the cascading adapter are as follows:
• Name of the adapter group
cascading-query-group-name-output-stream-name-M
The value in query-group-name indicates the name of the query group
that defines the stream that should be connected.
The value in output-stream-name indicates the name of the output stream
that is specified as stream-name in the stream.output.stream-
name.link property.
The value in M indicates a three-digit decimal number that displays the
serial number of the input stream of the connection destination. For
example, 001, 002, and so on.
• Name of the adapter
cascading[-N]
Internal adapters 79
Hitachi Streaming Data Platform

The number -N is only added for a scale-out configuration. The value of N
is one or more (three-digit decimal number, that is, the scale-up number,
such as 001, 002, and so on).
Stopping of adapters
When the query group is stopped, the adapters that were started
automatically are also stopped.
80 Internal adapters
Hitachi Streaming Data Platform

6
External adapters
This chapter provides information about the features of external adapters,
which are used for transmitting and receiving analysis data to and from SDP
servers respectively.
□
External input adapters
□
External output adapters
□
External adapter library
□
Connecting to parallel-processing SDP servers
□
Custom dispatchers
□
Heartbeat transmission
□
Troubleshooting
External adapters 81
Hitachi Streaming Data Platform

External input adapters
External input adapters send analysis data to SDP servers.
Overview of external adapters
Overview of external input adapters
Description
External adapters are used to send the data that should be analyzed to the
SDP server and to receive the results of the analysis from the SDP server.
External adapters get the address of the data-transmission stream or
reception-destination stream from the SDP broker and connect to the
corresponding target streams. If the SDP servers are running in a parallel
configuration, then the adapters connect all the servers. Therefore, While
developing external adapters, developers need not be aware of individual
SDP servers.
Note: You can also deploy external adapters into hosts other than SDP
servers.
External input adapters connect with TCP data input adapters, which are
available on an SDP server to send the data through the TCP IP protocol.
External output adapters
External output adapters receive analysis results from SDP servers.
82 External adapters
Hitachi Streaming Data Platform

Overview of external output adapters
Description
External output adapters receive analysis results from an SDP server. These
adapters connect with TCP cascading adapters on an SDP server to receive
data through the TCP protocol.
When the external output adapter receives data, the callback registered by
the external output adapter is called asynchronously. The integration
developer can process the received data by implementing processing on the
received data as a callback.
External adapter library
Integration developers use an external adapter library to create external
input and output adapters.
Overview of an external adapter library
Description
The external adapter library can be used to create an external input or output
adapter as a Java application.
Workflow for creating external input adapters
You can create an external input adapter by using the external adapter
library.
Flow of external input adapter operations and the implementation methods
and functions of the external adapter library
External adapters 83
Hitachi Streaming Data Platform

Description
The operations to be performed for creating an external input adapter are as
follows:
1. Configure the initial settings of the external adapter. Specify the path of
the external adapter-definition file.
Note:
The initial settings should be configured only once after the
external adapter has been started.
2. Connect to the input stream of an SDP server. If the SDP servers are
running in a parallel configuration (
*
), then the external adapter library
connects to all the input streams.
Note: *: This includes instances where the destination query
group has been registered using the count that was specified
during parallel processing.
3. Transmit data by sending the data to the input stream. If the destination
SDP server is running in a parallel configuration, then the specified SDP
server setting determines the data-dispatching method. However, if a
custom dispatcher is specified for the application, then the rules of the
custom dispatcher control the dispatching of data.
84 External adapters
Hitachi Streaming Data Platform

4. Disconnect the external adapter library from the input stream, when
there is no data to be sent to the input stream.
5. To terminate the operation of the external adapter, call the termination
method or function of the external adapter library.
An example of an external input-adapter program is available in the sample
file of Streaming Data Platform software development kit, which is available
at the following location:
/opt/hitachi/hsdp/sdk/samples/exadaptor/inputadaptor/src/
ExternalInputAdaptor.java
Workflow for creating external output adapters
You can create an external output adapter by using external adapter library.
Flow of external output adapter operations and the implementation methods
and functions of the external adapter library
External adapters 85
Hitachi Streaming Data Platform

Description
1. Configure the initial settings of the external adapter library. Specify the
path of the external adapter-definition file.
Note: The initial settings should be configured only once after the
external adapter has been started.
2. Find the output stream of an SDP server. If the SDP servers are running
in a parallel configuration, then the external adapter library tries to find
all the output streams.
3. Register a callback to conduct the data-receiving process. After the
callback has been registered, it connects to the output streams that were
found. You should set a wait time in the external adapter to ensure that
the callback registration is not cancelled until the analysis by the
connection destination has been completed. When the analysis of the
connection destination stops, cancel the callback registration.
4. Get the necessary data from the data notification that was received and
then sent to the callback. The data that was notified to the callback was
the data that was received after the callback was registered.
5. Cancel the registration of the callback to end the reception of data.
6. Disconnect from the output stream to end the reception from the output
stream.
7. To terminate the external adapter, perform the termination process of the
external adapter library.
Examples of external output-adapter programs are available in the sample
file of Streaming Data Platform software development kit, which is available
at the following location:
/opt/hitachi/hsdp/sdk/samples/exadaptor/outputadaptor/src/
ExternalOutputAdaptor.java
Creating callbacks
You can create callbacks by creating a class that implements the
HSDPEventListener interface and by describing the process that should be
performed during the callback in the onEvent() method.
Description
After you register the object of the class that implements the
HSDPEventListener interface by using the register() method of the
HSDPStreamOutput interface, the onEvent() method of the object that is
registered will be called back when a tuple is created on the SDP server.
86 External adapters
Hitachi Streaming Data Platform

An example of the callback program is available in the sample file of
Streaming Data Platform software development kit, which is available at the
following location:
/opt/hitachi/hsdp/sdk/samples/exadaptor/outputadaptor/src/
ExternalOutputAdaptor.java
Connecting to parallel-processing SDP servers
When SDP servers are running in a parallel configuration, an external adapter
gets all the addresses, which are used to connect to any targeted SDP server,
from the broker. Therefore, while developing external adapters, developers
need not consider individual SDP servers.
Using the timestamp-adjustment function to sort tuples in chronological
order
Description
The SDP server settings confirm the data-dispatching method used by the
external input adapter to send data to parallel-processing SDP servers. For
more information about each of the dispatching methods (for example,
hashing and round-robin), see
Cascading adaptor on page 64. Alternatively,
using the custom dispatcher, the dispatching method is determined by using
the external adapter settings rather than the SDP server settings. For more
information about custom dispatchers, see
Custom dispatchers on page 87
When an external output adapter receives data from multiple parallel-
processing SDP servers, the callback sends notifications (of the data) in the
order in which the data was received. These data notifications will not be in
chronological order. If you want to receive notifications in chronological order,
then the data must be sorted at the SDP server, which sends the data to the
external output adapter.
Custom dispatchers
Custom dispatchers enable you to determine the data-dispatching method at
the external adapter rather than at the SDP server.
Overview of a custom dispatcher
External adapters 87
Hitachi Streaming Data Platform

Description
Use custom dispatchers to determine the dispatching points based on
arbitrary configurations in external adapters.
Note: Do not use custom dispatchers to determine dispatching points based
on SDP standard dispatching methods.
The following conditions must be met to use custom dispatchers:
• A custom dispatcher has been created for external adapter files. These
files include .jar or .class file for Java.
• The stream.input.stream-name.dispatch.type=custom is set in the
query-group properties file of the destination SDP server.
Rules for creating class files
Class files that implement a custom dispatcher will use a constructor without
arguments to generate instances. Any package name or class name can be
specified.
Description
The following conditions must be met to create a class file:
• The value public must always be specified for the class modifier. Abstract
classes (abstract) are not available.
• Avoid instances where only the constructors with arguments are available
either by using the default constructor (do not create a constructor) or
creating a constructor without arguments. The value public (without
arguments) must always be specified for the modifier of the constructor.
Note: If the conditions required to create a class file are not met,
then no instance can be generated from a class file that is
implementing a custom dispatcher. This results in an error from the
loadDispatcher method of the HSDPStreamInput interface file,
which registers the custom dispatchers.
88 External adapters
Hitachi Streaming Data Platform

• The HSDPDispatch interface should be implemented in the class files that
implement a custom dispatcher. The following method must be
implemented by the interface:
public int dispatch(HSDPDispatchInfo dispatchInfo, byte[]
data);
• Implement a method that returns the IDs of the dispatching destinations.
Note: The IDs are assigned based on the number of destinations,
starting from 1. This applies to both the destinations in the scale-up
and scale-out configurations.
This method is driven by the execution of the put method of the
HSDPStreamInput interface file.
Ensure that the class name that contains the name of the class-file package
(which implements the custom dispatcher) is not the same class name as the
class file in the class path that is specified when the external adapter is run.
If both have the same name, when the external adapter is run, the class that
is specified in the class path takes precedence in loading and the external
adapter may not operate normally.
When the external adapter is run, the path of a class file that implements the
custom dispatcher should not be specified in the classpath for the external
adapter. If specified, you cannot replace the custom dispatcher while the
external adapter is running.
Examples of implementing dispatch methods
The Java and C external adapters are used as examples for implementing the
dispatch method of a custom dispatcher.
Description
Java external adapter
Implement a dispatch method that returns the IDs of the dispatching
destinations. An example of referencing integer-type initial columns to
determine the dispatch destinations is as follows:
public class Dispatcher implements HSDPDispatch {
@Override
public int dispatch(HSDPDispatchInfo dispatchInfo,
byte[] data) {
// Destination ID
int destID;
// The number of destinations
int destNum = dispatchInfo.getDestNum();
External adapters 89
Hitachi Streaming Data Platform

// The First column is of VARCHAR type (two byte
header + String -type data).
ByteBuffer buffer = ByteBuffer.wrap(data);
byte[] val1 = new byte[buffer.getShort()];
buffer.get(val1);
// Determine the destination.
destID = new String(val1).hashCode() % destNum + 1;
return destID;
}
}
Heartbeat transmission
The heartbeat() method is used to obtain the result of the latest data that
was transmitted from a query.
When an SDP server is running in the data source mode, the time of the SDP
server does not progress if the data to be input runs out. Therefore, there will
not be any output of an analysis result from the query. Therefore, there will
not be any output of an analysis result from the query.
This issue can be resolved by stopping the analysis and removing the target
stream from the query. Alternatively, you can send heartbeats at regular
intervals to make the time of the SDP server progress without stopping the
analysis. The heartbeat() method of the HSDPStreamInput interface in Java
can be used to send a heartbeat.
Troubleshooting
If an error occurs while the external adapter is running, then the message log
file and trace log file are output to the respective file locations. However, the
log file is not output before the init() method is run or after the term()
method of the HSDPAdaptorManager class is run.
Related topics
For more information about the file locations and specifications of log files,
see the Hitachi Streaming Data Platform Setup and Configuration Guide.
90 External adapters
Hitachi Streaming Data Platform

7
RTView Custom Data Adapter
The RTView Custom Data Adapter of Hitachi Streaming Data Platform
(hereinafter referred to as "HSDP") works with a third-party product,
Enterprise RTView (hereinafter referred to as "RTView") to make the analysis
results of the HSDP visible in real time.
□
Setting up the RTView Custom Data Adapter
□
Environment setup
□
Editing the system definition file
□
Environment variable settings
□
Data connection settings
□
Uninstallation
□
File list
□
Operating the RTView Custom Data Adapter
RTView Custom Data Adapter 91
Hitachi Streaming Data Platform

Setting up the RTView Custom Data Adapter
When setting up a system that displays analysis results in the RTView
window, you can use the RTView Custom Data Adapter of HSDP (hereinafter
referred to as "RTView Custom Data Adapter") to specify data from the SDP
server as a data source for RTView. By configuring the settings of the RTView
Custom Data Adapter, you can reduce the number of work hours necessary to
set up a system that acquires the analysis results of HSDP and displays them
in the RTView window (you do not need to develop a user application to
acquire data from the SDP server, and to register and display the data in
RTView).
The following diagram illustrates how the RTView Custom Data Adapter
works.
Figure 33 Employment of the RTView Custom Data Adapter
After the data is analyzed in real time on the SDP server, it is automatically
collected by the RTView Custom Data Adapter (installed together with
RTView) on the host RTView is running, processed to suit the RTView
interface, and then displayed in the RTView window. In detail, the custom
data adapter added on the RTView receives data from dashboard output
connector on HSDP.
Environment setup
If the system operator uses the dashboard adapter on the dashboard server
(such as RTView), the system operator needs to set up the dashboard
adapter.
Installation
92 RTView Custom Data Adapter
Hitachi Streaming Data Platform

Prerequisites
The RTView Custom Data Adapter must be installed on a machine on
which RTView is installed.
Procedure
The RTView Custom Data Adapter files are included in the HSDP
package. No RTView Custom Data Adapter installer is available. Copy
the files stored on the project to a folder in the machine that is to run
RTView with the RTView Custom Data Adapter.
Procedure
1. Transfer the dashboard adapter library file.
Transfer the following file with a file transfer method such as the scp
command to the host on which the RTView runs:
/opt/hitachi/hsdp/conf/hsdpcdalib.tar.gz
2. Extract files from the dashboard adapter library file.
Extract the files from the dashboard adapter library file with a
decompression method such as the tar command, and put all of them in
the same directory.
For details on the RTView Custom Data Adapter files, see section
File list
on page 98.
Editing the system definition file
After installing the RTView Custom Data Adapter, edit the system definition
file as needed. Parameters for the dashboard adapter are defined in the
ucsdpcda_config.properties file that was one of the extracted files. In the
RTView Custom Data Adapter system definition file, specify the host of SDP
server and port number used to connect to a dashboard output connector of
HSDP.
To set parameters for the dashboard adaptor, edit the
ucsdpcda_config.properties file manually or run the hsdpcdaset
command for the extracted file. The value of the
ucsdpcda_config.properties file can be changed by running the
hsdpcdaset command.
For the detail about the hsdpcdaset command, see Hitachi Streaming Data
Platform Setup and Configuration Guide.
RTView Custom Data Adapter 93
Hitachi Streaming Data Platform

File name
The following table shows the name of the RTView Custom Data Adapter
system definition file.
Table 19 System definition file
File Name Description Path
ucsdpcda_config.properties RTView Custom Data Adapter system
definition file
Folder where the file is
copied, as explained in
Environment setup on
page 92 .
Definition format
The RTView Custom Data Adapter system definitions must be specified in the
Java property format (key=value).
Definition items
The following table describes the definition items of the RTView Custom Data
Adapter system definition file.
Table 20 System definition of RTView Custom Data Adapter
key
Type Value Description
serverName String indicating the
server name
1 to 255 byte
characters (in bytes)
(Required)
Specify the IP address
or host name of the
HSDP server on which
the dashboard output
connector runs.
If the specified name is
invalid, KFSP46902-W
will be output.
portNo Numeric value
indicating the port
number
Numeric value in the
range from 1024 to
65535
(Optional)
The default value is
20421.
Specify the port
number for RMI
connection to the
dashboard output
connector on the SDP
server.
If the specified value is
invalid, KFSP46902-W
will be output, and the
default value will be
set.
communicateRetryInt
erval
Numeric value
indicating the retry
interval (in
milliseconds) for RMI
connection
0 or a numeric value in
the range from 1000 to
922337203685477580
7
(Optional)
The default value is
10000.
Specify the retry
interval (in
milliseconds) for RMI
connection when the
connection to the
dashboard output
connector on the HSDP
server is disconnected.
94 RTView Custom Data Adapter
Hitachi Streaming Data Platform

key Type Value Description
If 0 is set, the
dashboard adaptor will
not attempt to re-
establish the RMI
connection.
Definitions
An example of the RTView Custom Data Adapter system definition file is as
follows:
serverName = StreamServer
portNo = 20421
Note:
• Copy the RTView Custom Data Adapter system definition file to the
directory where you start the RTView (RTView Display Builder or RTView
Display Viewer).
• If the specified server name is invalid, the specified server name and port
number are ignored. In such a case, the error messages (KFSP46911-W to
KFSP46914-W) will contain the text "server name = null, port number =
0".
Environment variable settings
You must set the RTView environment variables before using the RTView
Custom Data Adapter. On the machine on which the RTView Custom Data
Adapter is installed, set the RTV_USERPATH environment variable used by
RTView as follows:
directory-to-which-the-file-is-copied
\sdpcda\lib\sdpcda.jar;
In the RTV_USERPATH environment variable, set the absolute path of
sdpcda.jar, which is provided when the RTView Custom Data Adapter is
installed.
Data connection settings
At building displays with RTView display builder, configure the connection
settings to connect the HSDP output to the tables and graphs that will be
displayed on the screen.
RTView Custom Data Adapter 95
Hitachi Streaming Data Platform

1. Click Attach to Data to connect an object property to your data source for
each object and to display the analysis results in the window created in
RTView Display Builder, such as tables and graphs.
2. 2. In the selection dialog box, from list of active data sources, select
HITACHI_STREAM as the data source name for HSDP.
Figure 34 Selecting Custom Data Adapter
After specifying the data source to connect, in the Attach to Data dialog
box, specify the analysis data to be displayed in objects, such as tables
96 RTView Custom Data Adapter
Hitachi Streaming Data Platform

and graphs. The items to be specified in the Attach to Data dialog box
are as follows:
Figure 35 Attach to Data dialog box
Field
Description
Name Either manually enter the distinguished name to identify the
dashboard output connector containing the data that you want to
display, or select the appropriate name from the list.
For you to select a distinguished name from the list, at least one
dashboard output connector must be started before you open the
dialog box. If you specify a nonexistent distinguished name in
this field, after you confirm the entry by pressing the Enter key
or by moving to another field, the background color turns red. (If
you enter an existing name, the background color turns white.
Column(s) Either manually enter the column name, or select it from the list.
To select a column name from the list, the dashboard output
connector that corresponds to the distinguished name specified
in the Data Name field must be started before you open the
dialog box.
If you specify a nonexistent column name in this field, after you
confirm the entry by pressing the Enter key or moving to
another field, the background color turns red. (If you enter an
existing name, the background color turns white.)
Notes
- In Attach to Data dialog box, the field surrounded by the dotted line is
provided by the RTView Custom Data Adapter, and the other fields are
provided by RTView. For details, see the RTView documentation.
RTView Custom Data Adapter 97
Hitachi Streaming Data Platform

- If you enter a nonexistent distinguished name in the Data Name field,
the Column field will not be updated. After you enter an existing
distinguished name in the Data Name field, the corresponding column
names are automatically entered in the Column field. Reconfigure the
column as needed.
Uninstallation
To uninstall the RTView Custom Data Adapter, manually delete the files that
you copied from the media during installation.
File list
The RTView Custom Data Adaptor files are stored in the directory:
HSDP-installation-directory/conf/hsdpcdalib.tar.gz
For Dashboard adaptor library file detail see Hitachi Streaming Data Platform
Setup and Configuration Guide.
Table 21 File list
File name
Description
sdpcda.jar Library
ucsdpcda_config.properties System definition file
HITACHI_STREAM.properties Resource file
The following table shows the jar component of the RTView Custom Data
Adaptor.
Table 22 jar component list
File Name
jar component Description
sdpcda.jar jp.co.Hitachi.soft.sdp.cda.Sdpc
da
RTView Custom Data Adapter
Operating the RTView Custom Data Adapter
Types of operations
The following table lists the types of operations.
Table 23 Types of operations
Operation
Description Procedure
98 RTView Custom Data Adapter
Hitachi Streaming Data Platform

Starting the RTView Custom
Data Adapter
Start the RTView Custom Data
Adapter.
(1) Prepare the RTView
Custom Data Adapter
(2) Start the RTView Display
Viewer*
Stopping the RTView
Custom Data Adapter
Stop the RTView Custom Data Adapter. (1) Stop the RTView Display
Viewer*
Changing the analysis
settings
As needed, change the RTView Custom
Data Adapter settings according to
change in analysis settings of HSDP.
(1) Stop the RTView Display
Viewer*
(2) Prepare the RTView
Custom Data Adapter
(3) Start the RTView Display
Viewer*
* During normal operation, if you are using the RTView Display Builder to
monitor real-time analysis results, you start and stop the RTView Display
Builder.
Operation procedure
The RTView Custom Data Adaptor Adapter operation procedure is as follows.
Procedure
1. Editing the system definition file:
Edit the RTView Custom Data Adapter system definition file to match
your environment.
For details about the system definition file, see
Editing the system
definition file on page 93.
2. Copying the files:
Copy the RTView Custom Data Adapter system definition and resource
files to the project directory for RTView where you will run the RTView
(RTView Display Builder or RTView Display Viewer).
For details about the files, see the
file list on page 98.
3. Starting HSDP:
Start HSDP.
For details, see Hitachi Streaming Data Platform Setup and Configuration
Guide.
Starting the RTView Custom Data Adapter
This topic explains the command execution procedure for starting the RTView
Custom Data Adapter. The RTView Custom Data Adapter runs in the RTView
Display Builder or RTView Display Viewer process.
RTView Custom Data Adapter 99
Hitachi Streaming Data Platform

Procedure
1. At the command prompt, execute the RTView Display Builder or RTView
Display Viewer startup command provided by RTView with specifying the
RTView Custom Data Adapter component name
(jp.co.Hitachi.soft.sdp.cda.Sdpcda) as an argument of the command.
2. If an incorrect procedure was used to start the system, stop and restart
the system following correct procedures.
3. To start RTView Display Builder:
run_builder -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda
4. To start RTView Display Viewer:
run_viewer -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda display-file-name
or
run_viewer -customds:jp.co.Hitachi.soft.sdp.cda.Sdpcda display-file-name.rtv
Stopping the RTView Custom Data Adapter
Procedure
1. Stop the RTView Display Builder or the RTView Display Viewer.
For details on how to stop the RTView Display Builder or the RTView
Display Viewer, see the RTView documentation. Data that needs to be
collected for each event below lists the data that need to be collected for
events:- When an error message is displayed:When an internal system
error occurs or when an illegal execution exception occurs- When the
server process terminates:The server process terminates: When the
JavaVM process of the RTView Display Viewer unexpectedly terminates
without a message being output- When the analysis results cannot be
acquired:The analysis results cannot be acquired: When the analysis
results are not output to the RTView Display Viewer
Result
Table 24 Data that needs to be collected for each event
Data
Action When an error
message is
displayed
When the server
process
terminates
When the analysis
results cannot be
acquired
Standard output,
standard error
output
Retrieve the
standard output /
standard error
output
information.
Must be collected Must be collected Must be collected
System definition
file
Retrieve the file
listed in System
Must be collected Must be collected Must be collected
100 RTView Custom Data Adapter
Hitachi Streaming Data Platform

definition file
location.
Table 25 System definition file
RTView Custom Data Adapter system definition file
project-directory/ucsdpcda_config.properties
RTView Custom Data Adapter 101
Hitachi Streaming Data Platform

102 RTView Custom Data Adapter
Hitachi Streaming Data Platform


Data-parallel configurations
The division of an analysis-scenario process into multiple processes or
threads is called 'data parallel'. A data-parallel configuration enables the load
balancing of the query process thus resulting in a higher performance.
By using a data-parallel configuration you can distribute the load of the
processing of the analysis-scenario queries. This distribution will help you
analyze data at a higher speed when compared to a configuration that runs
analysis scenarios in a single process or thread.
Data-parallel system configurations include scale-up and scale-out
configurations. The figure illustrates the details of scale-up and scale-out
configurations. It also illustrates the modification of a configuration
(comprising query groups 1 and 2) into a data-parallel configuration.
Scale-up configuration
In a scale-up configuration, query groups analyze (in parallel) multiple
threads (that are to be processed) of an SDP server. If there are sufficient
CPU resources for process-multiplexing but the usage of memory resources
should be limited, then to establish a high-performance system choose a
scale-up configuration instead of a scale-out configuration.
Scale-up configuration for processing query groups
Description
The figure illustrates the scale-up configuration for processing query groups 1
and 2. In this configuration, the relevant data is transmitted separately from
the external input adapter to each query group.
104 Scale-up, scale-out, and data-parallel configurations
Hitachi Streaming Data Platform

(a) Usage method
Query groups can be registered by running the hsdpcql command with
the scale-up number in the –thread option.
(b) Query group name
When you use the -thread option of the hsdpcql command to specify
the scale-up number as 2 or more for registering query groups, the
query groups with the following names are registered on the SDP server.
These query groups correspond to the threads that are running parallel
on the SDP server.
defined-query-group-name-N
defined-query-group-name: Query group name to be specified in the
hsdpcql command
N: From 1 to the scale-up number (three-digit decimal number)
(c) Internal standard adapters
When you use the hsdpstartinpro command to start internal standard
adapters, a single adapter is started (irrespective of the availability of a
scale-up configuration). In the adapter-definition file, you must specify
the definition for connecting to the query group as detailed in the query
group name. To run the adapters in scale-up query groups, run the
hsdpstartinpro command multiple times. The number of times that the
command is run must be equal to the scale-up number.
While connecting internal standard adapters from an external adapter
(or due to any other trigger), the number of adapters equal to the
number of scaled-up query groups are started automatically by HSDP.
When the internal standard adapters are started automatically by HSDP,
the number of adapters equal to the number of scaled-up query groups
are started automatically at the time of connection from the external
adapter (or due to another trigger).
(d) Internal custom adapters
Unlike standard adapters, when query groups start or when the
hsdpstartinpro command is used to start internal adapters, only a
single custom adapter is started. The names of the query groups, which
have to be accessed by the custom adapter can be obtained based on
the query group names that are defined by using the APIs as specified in
the Hitachi Streaming Data Platform Application Development Guide.
When the hsdpstartinpro command is used to start a custom adapter,
only one custom adapter is started regardless of whether there is a
scale-up configuration. For the name of the query group to which the
Scale-up, scale-out, and data-parallel configurations 105
Hitachi Streaming Data Platform

custom adapter connects, you should specify the query group name as
specified in the Query group name section.
Scale-out configuration
A scale-out configuration analyzes (in parallel) query groups in multiple SDP
server processes. If there are sufficient CPU and memory resources for
multiplexing, then to establish a high-performance system, choose a scale-
out configuration instead of a scale-up configuration.
Scale-out configuration for processing query groups
Description
The figure illustrates the scale-out configuration for processing query groups
1 and 2. In this configuration, the relevant data is transmitted separately
from the external input adapter to each query group.
• Usage method
Multiple working directories that have the same server cluster name on the
hosts of the same coordinator group and register query groups that have
the same query group name can be created. After creating the working
directories, start the query groups. It is also possible that a scale-out
configuration is present between multiple hosts.
• Internal standard adapters
An internal standard adapter can be used by running the hsdpstartinpro
command, which starts the adapters in the working directories that
comprise the scale-out configuration. When the adapters are connected by
an internal or external adapter, the internal standard adapters (available in
all the working directories) of the scale-out configuration are started
automatically by Streaming Data Platform.
• Internal custom adapters
In a scale-out configuration, the internal custom adapters (developed by
you) can be used by running the hsdpstartinpro command, which starts
the adapters in the working directories that comprise the scale-out
configuration.
106 Scale-up, scale-out, and data-parallel configurations
Hitachi Streaming Data Platform

Data-parallel settings
A data-parallel configuration requires an adapter to distribute data to the
input streams of query groups that are running in parallel.
Description
Query groups can be used in a data-parallel configuration by specifying the
method of the input-stream distribution in the query-group properties file of
the query groups that are running in parallel.
Scale-up, scale-out, and data-parallel configurations 107
Hitachi Streaming Data Platform

108 Scale-up, scale-out, and data-parallel configurations
Hitachi Streaming Data Platform

9
Data replication
This chapter provides information about the data-replication feature, which
enables an adapter to send the same data to multiple destination streams.
The data-replication feature is available in the external input adapters and
internal cascading adapters. The data-replication method is different from the
ALL distribution method of the cascading adapter. Data replication is used to
transmit the same data to different input streams, and the distribution
method is a function used to transmit identical data to input streams that are
running in parallel, in a data-parallel configuration.
Related topics
For more information about examples of using data replication and setting up
data replication, see
Examples of using data replication on page 110 and
Data-replication setup on page 111 respectively.
For more information about the ALL distribution method, see Figure 28 All
overview on page 70.
□
Examples of using data replication
□
Data-replication setup
Data replication 109
Hitachi Streaming Data Platform

Examples of using data replication
The data-replication feature is used for analysis in task-parallel configurations
and while using a redundant configuration with two active systems (system
redundancy).
Example of a task-parallel configuration
Example of system redundancy configuration
Description
Examples of the data-replication feature are as follows.
110 Data replication
Hitachi Streaming Data Platform

Table 26 SDP system components
S. No. Example Description
1 Analysis in task-parallel configurations A task-parallel configuration analyzes a data set
through multiple analysis methods. This analysis
can be achieved by using the data-replication
feature. It is possible to create a task-parallel
configuration by using the data-replication
feature.
2 System redundancy When there are two active systems, a redundant
configuration is used to achieve higher system
availability. Identical data is sent to the
respective systems and identical analysis is
performed in the respective coordinator groups.
Even if one system stops, the analysis will be
performed in the other system.
Data-replication setup
The data-replication feature can be used by setting multiple destination
streams in the definition file of each adapter. However, to set up a redundant
system with two active flows, the input streams must be assigned to different
broker addresses for managing different coordinator groups.
Example of data replication performed by an external input adapter
Example of system redundancy configuration
Data replication 111
Hitachi Streaming Data Platform

Description
The following table provides information about the actions to be performed
when specific adapters are used to replicate data.
Types of
adapters
Action Example
External input
adapter
When an external input adapter
performs data replication, specify
(using commas as delimiters) multiple
streams to send the same data to the
destination stream definition in the
external input adapter-definition file.
target.name.1= /
192.168.12.40:20425/qg1/
s1,/192.168.12.41:20425/qg1/s1
If you assign target.name.1 to the
StreamInput() method of the
HSDPAdaptorManager class, then the
same data is sent to multiple
destinations.
Identical data can be sent to multiple
destinations by specifying
target.name.1 for the
openStreamInput() method of the
HSDPAdaptorManager class.
Internal cascading
adapter
When an internal cascading adapter
performs data replication, specify
(using commas as delimiters)
multiple-destination input streams for
the output streams in the query-group
definition file.
stream.output.q1.link=qg1/
s1,qg2/s1
112 Data replication
Hitachi Streaming Data Platform

10
Setting parameter values in definition
files
This chapter provides information about the relationship between parameter
values and definition files. It also provides examples of setting parameter
values in query-definition files.
□
Relationship between parameters files and definition files
□
Examples of setting parameter values in query-definition files and query-
group properties files
□
Adapter schema automatic resolution
Setting parameter values in definition files 113
Hitachi Streaming Data Platform

Relationship between parameters files and definition files
The parameter values of any SDP-definition file items can be set up, as
required. The parameter values (that allows you to separate definitions into
those you want to modify or keep fixed) that are set in a parameters file are
collected which results in simpler definition design and configurations.
Merging values from multiple parameters files into a definition file
The example given shows the usage of the same key name in multiple
parameters files. If there are multiple parameters files, then SDP loads the
parameters files in ascending order of the file names in ASCII code.
If an identical key name is used in multiple parameters files, then the value
of the file that is loaded later is used.
Merging values (through analysis) from a parameters file to multiple
definition files
114 Setting parameter values in definition files
Hitachi Streaming Data Platform

Description
The parameter values can be set for the content of an SDP-definition file.
The actual values of the sections for which the parameter values have to be
set should be specified. These actual values are specified in the key-value
format in a separate file called the "parameters file".
By setting the parameter values, you can clearly differentiate between the
parts that have to be fixed and that have to be tuned in the definition file. To
set identical values in multiple definition files, set the parameter values,
which enables you to consolidate the parts to be modified.
The file names and storage locations of the definition files should follow the
specifications of the definition files. This should not be modified once the
parameter values have been set. A parameters file with the extension .param
should be created and stored in the HSDP-installation- directory/conf/
directory.
While loading a definition file for which the parameter values can be set, SDP
merges the content of the parameters file into the definition file. Similarly,
while merging the files, SDP replaces the parts for which the parameter
values have been set with the values that have been specified in the
parameters file. Once the files are merged, SDP runs according to the content
of the merged definition file. The content of the merged definition file is
stored in a separate file (using the file name of the definition file and the file
extension .out) and output to the same directory of the definition file. If a
file with the same name exists, then this file (which contains the content of
the merged definition file) is overwritten. You can refer to the output file to
verify the replacement result.
The file with the extension .out remains even after SDP has stopped. If you
want to delete this file, then delete after SDP has stopped. Additionally, do
Setting parameter values in definition files 115
Hitachi Streaming Data Platform

not modify the content of this file because it can be used as a reference to
verify the replacement result.
List of definition files for which parameter values can be set
The definition files for which the parameter values can be set are as follows:
Note: Parameter values cannot be set for definition files that are not listed. If
such files do accept parameter values, then an error occurs when you run the
command.
• Query-definition file
• Query-group properties file
• External-definition function file
• Adaptor-composition definition file
Examples of setting parameter values in query-definition
files and query-group properties files
While setting parameter values in query-definition files, the names and
storage locations of the definition files must not be modified. The names and
storage locations must conform with the specifications of each definition file.
The parameters files with the extension .param should be stored in the
working directory/conf/ directory. By using the SDP command, the
related definition files and all the parameters files are loaded and analyzed
(merged) in the working directory/conf directory. After analysis
(merging), the definition files are output to the same directory (definition-
file-name) in which the definition files are stored. The output files are stored
with the extension .out. The .out files are only for your reference. The
commands do not load or analyze files that have been modified. If you want
to modify the contents of the definitions, then edit definition files (for which
parameters have been set) and parameters file.
Examples of query-group properties files (with and without parameters) and
parameters files (with the extension .param)
For more information about the formats of definition files and parameter files,
see the Hitachi Streaming Data Platform Setup and Configuration Guide.
Query-group properties file (without parameters)
querygroup.cqlFilePath=/home/user1/wk1/query/q001
stream.input.S1.dispatch.type= hashing
stream.input.S1.dispatch.rule= column11,column12,column13
stream.input.S2.dispatch.type= hashing
stream.input.S2.dispatch.rule= column21,column22
:
(snip)
116 Setting parameter values in definition files
Hitachi Streaming Data Platform

Query-group properties file (with parameters)
querygroup.cqlFilePath=${cqlFilePath}
stream.input.S1.dispatch.type=${S1_type}
stream.input.S1.dispatch.rule=${S1_rule}
stream.input.S2.dispatch.type=${S2_type}
stream.input.S2.dispatch.rule=${S2_rule}
:
(snip)
Parameters files (with the extension .param)
cqlFilePath=/home/user1/wk1/query/q001
S1_type=hashing
S1_rule=column11,column12,column13
S2_type=hashing
S2_rule=column21,column22
:
(snip)
Adapter schema automatic resolution
With adapter schema auto resolution, the user need not specify the schema
information regarding the data in the adapter-configuration definition file.
Additionally, it gets the schema information about the data from the query
group and the stream of the connection destination to automatically resolve
the schema information about the data handled by the adapter.
Description
When the standard adapter that comes with SDP is used, the schema of the
input or output data of the query group in the adapter-configuration
definition file should be defined in advance to exchange tuples with the query
group. However, if the data to be sent and received by the adapter has the
same data structure as that of the input and output data of the query group,
then this definition can be ignored.
By modifying the template that comes with the HSDP, an adapter-
configuration definition file for the standard adapter should be created by the
user. Additionally, the user has to specify the connection-destination query
group name and stream name in the command, when the adapter is started.
The user need not retain information regarding the schema of the data that
will be input to or output from the query group.
When this function is used, the definitions of multiple SDP standard adapters
in a single adapter-configuration definition file should not be included. To
create multiple adapters, a separate adapter-configuration definition file for
each adapter should be created. If multiple adapters are included in a single
adapter-configuration definition file, then SDP resolves the schema
information such that all adapters included in the adapter-configuration
definition file connect to the same single stream.
Setting parameter values in definition files 117
Hitachi Streaming Data Platform

Some examples of the adapter-configuration definition file of the TCP data
input adapter in which the user describes the schema and where the schema
is automatically resolved, are as follows.
Content of the query definition file to input data from the TCP-data input
adapter to the input query group:
register stream DATA0(name VARCHAR(10), num BIGINT);
register query FILTER1 ISTREAM(SELECT name FROM DATA0[ROWS 1]);
Content of the adapter-configuration definition file in which the schema has
been described by the user:
<?xml version="1.0" encoding="UTF-8"?>
<!-- All Rights Reserved. Copyright (C) 2016, Hitachi, Ltd. -->
<root:AdaptorCompositionDefinition
xmlns:root="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition"
xmlns:cmn="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/common"
xmlns:adp="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/adaptor"
xmlns:cb="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback"
xmlns:ficon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FileInputConnectorDefinition"
xmlns:docon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/DashboardOutputConnectorDefinition"
xmlns:focon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FileOutputConnectorDefinition"
xmlns:form="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FormatDefinition"
xmlns:scon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/SendConnectorDefinition"
xmlns:rcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ReceiveConnectorDefinition"
xmlns:tocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/SNMPTrapOutputConnectorDefinition"
xmlns:smtpocon="http://www.hitachi.co.jp/soft/xml/sdp/
adaptor/definition/callback/SMTPOutputConnectorDefinition"
xmlns:tcpicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/TcpDataInputConnectorDefinition"
xmlns:dscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/DistributedSendConnectorDefinition"
xmlns:caclcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/CascadingClientConnectorDefinition"
xmlns:lwicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ForwardingInputConnectorDefinition"
xmlns:lwscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ForwardingSendConnectorDefinition"
>
<cmn:CommonDefinition>
<cmn:AdaptorTraceDefinition/>
</cmn:CommonDefinition>
<adp:InprocessGroupDefinition name="tcp">
118 Setting parameter values in definition files
Hitachi Streaming Data Platform

<adp:InputAdaptorDefinition name="tcp" charCode="UTF-8"
lineFeed="LF" language="Java">
<cb:InputCBDefinition
class="jp.co.Hitachi.soft.sdp.adaptor.callback.io.tcpinput.TcpDat
aInputCBImpl" name="Inputer">
<tcpicon:TCPDataInputConnectorDefinition>
<tcpicon:input port="25452" charCode="ASCII">
<tcpicon:binary>
<tcpicon:data name="NAME"
type="STRING" size="10" />
<tcpicon:data name="NUM" type="LONG"
size="8" />
</tcpicon:binary>
</tcpicon:input>
<tcpicon:output>
<tcpicon:record name="RECORD">
<tcpicon:fields>
<tcpicon:field name="NAME" />
<tcpicon:field name="NUM" />
</tcpicon:fields>
</tcpicon:record>
</tcpicon:output>
</tcpicon:TCPDataInputConnectorDefinition>
</cb:InputCBDefinition>
<cb:SendCBDefinition
class="jp.co.Hitachi.soft.sdp.adaptor.callback.sendreceive.SendCo
nnectorCBImpl" name="Sender">
<scon:SendConnectorDefinition>
<scon:streamInputs>
<scon:streamInput>
<scon:record name="RECORD" />
<scon:stream name="DATA0"
querygroup="Inprocess_QueryGroupTest" />
</scon:streamInput>
</scon:streamInputs>
</scon:SendConnectorDefinition>
</cb:SendCBDefinition>
</adp:InputAdaptorDefinition>
</adp:InprocessGroupDefinition>
</root:AdaptorCompositionDefinition>
Content of the adapter-configuration definition file in the automatic schema
resolution format is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<!-- All Rights Reserved. Copyright (C) 2016, Hitachi, Ltd. -->
<root:AdaptorCompositionDefinition
xmlns:root="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition"
xmlns:cmn="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/common"
xmlns:adp="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/adaptor"
xmlns:cb="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
Setting parameter values in definition files 119
Hitachi Streaming Data Platform

definition/callback"
xmlns:ficon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FileInputConnectorDefinition"
xmlns:docon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/DashboardOutputConnectorDefinition"
xmlns:focon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FileOutputConnectorDefinition"
xmlns:form="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/FormatDefinition"
xmlns:scon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/SendConnectorDefinition"
xmlns:rcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ReceiveConnectorDefinition"
xmlns:tocon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/SNMPTrapOutputConnectorDefinition"
xmlns:smtpocon="http://www.hitachi.co.jp/soft/xml/sdp/
adaptor/definition/callback/SMTPOutputConnectorDefinition"
xmlns:tcpicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/TcpDataInputConnectorDefinition"
xmlns:dscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/DistributedSendConnectorDefinition"
xmlns:caclcon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/CascadingClientConnectorDefinition"
xmlns:lwicon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ForwardingInputConnectorDefinition"
xmlns:lwscon="http://www.hitachi.co.jp/soft/xml/sdp/adaptor/
definition/callback/ForwardingSendConnectorDefinition"
>
<cmn:CommonDefinition>
<cmn:AdaptorTraceDefinition/>
</cmn:CommonDefinition>
<adp:InprocessGroupDefinition name="tcp">
<adp:InputAdaptorDefinition name="tcp" charCode="UTF-8"
lineFeed="LF" language="Java">
<cb:InputCBDefinition
class="jp.co.Hitachi.soft.sdp.adaptor.callback.io.tcpinput.TcpDat
aInputCBImpl" name="Inputer">
<tcpicon:TCPDataInputConnectorDefinition>
<tcpicon:input port="25452" charCode="ASCII">
<tcpicon:binary>
${hsdp_adp_tcpBinary}
</tcpicon:binary>
</tcpicon:input>
<tcpicon:output>
<tcpicon:record name="RECORD">
<tcpicon:fields>
${hsdp_adp_tcpFields}
</tcpicon:fields>
</tcpicon:record>
</tcpicon:output>
</tcpicon:TCPDataInputConnectorDefinition>
</cb:InputCBDefinition>
<cb:SendCBDefinition
120 Setting parameter values in definition files
Hitachi Streaming Data Platform

class="jp.co.Hitachi.soft.sdp.adaptor.callback.sendreceive.SendCo
nnectorCBImpl" name="Sender">
<scon:SendConnectorDefinition>
<scon:streamInputs>
<scon:streamInput>
<scon:record name="RECORD" />
<scon:stream name="$
{hsdp_adp_inputStreamName}" querygroup="$
{hsdp_adp_inputQueryGroupName}" />
</scon:streamInput>
</scon:streamInputs>
</scon:SendConnectorDefinition>
</cb:SendCBDefinition>
</adp:InputAdaptorDefinition>
</adp:InprocessGroupDefinition>
</root:AdaptorCompositionDefinition>
As mentioned in these examples, in an adapter-configuration definition file
used for automatic schema resolution, the schema information can be
resolved automatically by setting the parameter values of the sections for
describing schema information by using specific variable names.
In addition to the schema information, you can also set the parameter values
of the name of the query group connected by the adapter and the name of
the stream. The actual query group name and stream name that you specify
when the adapter is started are automatically placed into the query group
name and stream name, which have set parameter values.
Setting parameter values in definition files 121
Hitachi Streaming Data Platform

122 Setting parameter values in definition files
Hitachi Streaming Data Platform


Log-file generation
The logger feature is used to output messages from SDP components to log
files.
Description
The log files that are output by the logger are as follows.
For more information about log files, see the Hitachi Streaming Data Platform
Setup and Configuration Guide.
Table 27 Log files generated by the logger
S. No.
Components Generated log files Reference
1 Common Command
hsdpcommandmessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
2 Logger
hsdpservermessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
3 SDP server
SDPServerMessageN
1
.log
SDPServerCMessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
4 Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
5 Internal adapter
ADP_XXX
2
-
AdaptorMessageN
1
.log
ADP_XXX
2
-
AdaptorCMessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
6 External adapter
ExAdaptorMessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
7 SDP broker
BrokerMessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
8 SDP coordinator
CoordinatorMessageN
1
.log
Hitachi Streaming
Data Platform
124 Logger
Hitachi Streaming Data Platform

S. No. Components Generated log files Reference
Setup and
Configuration
Guide
9 SDP manager
ManagerMessageN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
10 hsdpsetup command
hsdpsetup.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
hsdpmanagersetup.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
11 hsdpexport command
hsdpexport.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
12 hsdpmanager command
hsdpmanagercommandmessag
eN
1
.log
Hitachi Streaming
Data Platform
Setup and
Configuration
Guide
• 1 : Serial number for the message log file.
• 2 : Name of the adapter group.
Logger 125
Hitachi Streaming Data Platform

126 Logger
Hitachi Streaming Data Platform

Glossary
This section lists the terms that are referenced in this manual.
adaptor
A program required to exchange data between input sources, output
destinations and the stream data processing engine.
Adaptor types include the standard adaptors provided with the product,
and custom adaptors that you can program in Java.
Each of these adaptor types are further classified into input adaptors,
which are used between input data and the stream data processing
engine; and output adaptors, which are used between the stream data
processing engine and output data.
adaptor definition file
A file used to configure the operation of standard adaptors. It specifies
details about the organization of the adaptor groups, and the I/O
connectors used by the adaptors.
adaptor group
A group of I/O adaptors. Standard adaptors operate in adaptor groups.
Adaptor groups that implement in-process connections are called in-
process adaptor groups.
built-in functions
Functions provided by HSDP. These include built-in aggregate functions
that provide statistical functions and built-in scalar functions that
provide mathematical and string functions.
callback
A processing unit that controls the functionality provided in the standard
adaptors.
common record
An internal record format that enables records to be processed by a
stream data processing system.
connector
An interface defined in the standard adaptors for connecting Streaming
Data Platform to the outside world.
For input to Streaming Data Platform, the file input connector and the
HTTP packet input connector are provided. For output from Streaming
Data Platform, the file output connector is provided.
Glossary 1
Hitachi Streaming Data Platform

CQL (Continuous Query Language)
A query language designed for writing continuous queries.
custom adaptor
An adaptor created by the user with the Java APIs provided by
Streaming Data Platform.
data reception application
A client application that performs event processing on stream data
output by an SDP server.
data source mode
A mode for assigning timestamps to tuples. In this mode, when the log
file or other data source being input contains time information, that time
information is assigned to the tuple.
data transmission application
A client application that sends stream data to an SDP server.
external definition function
A function that is created by a user with tools such as the Java API. Any
processing can be performed by implementing the processing logic for
the external definition function as a method in the class file created by a
user with Java.
external definition function file
A file that defines a class on which external definition function
processing is implemented and a method.
field
The basic unit of value in a record.
in-process connection
An architecture for connecting adaptors and SDP servers. Adaptors and
SDP servers that run in the same process use an in-process connection
to exchange data.
input record
A record that is read when the input source is a file.
input relation
A tuple group retrieved by means of a window operation. A relation
operation is then performed on the tuple group.
intermediate relation
A tuple group retrieved by the WHERE clause during relation operation
processing.
2 Glossary
Hitachi Streaming Data Platform

operator
The smallest unit of stream data processing. A query consists of one or
more operators.
output record
A record format for outputting stream data processing results to a file.
output relation
A tuple group output from a relation operation. A stream operation is
then performed on the tuple group.
query
Code that defines the processing to perform on stream data. Queries are
written using CQL.
query group
A stream data summary analysis scenario created in advance by the
user. A query group consists of an input stream queue (input stream),
an output stream queue (output stream), and relational queries.
record
A single row of data handled by stream data processing.
record organization
An organization expressed as a particular combination of two or more
fields (field names and their associated values).
relation
A set of records with a given life span. Using a CQL window specification,
records are converted from stream data to a relation that will persist for
the amount of time specified in the window operation.
relation operation
An operation that specifies what processing is to be performed on the
data retrieved by a window operation. Available actions include
calculation, summarization, joining, and others.
SDP server
A server process running a stream data processing engine to process
stream data.
SDP server definition file
A file used to configure SDP server operations. It specifies settings such
as the Java VM startup options for running an SDP server and adaptors,
and SDP server port numbers.
server mode
Glossary 3
Hitachi Streaming Data Platform

A mode for assigning timestamps to tuples. In this mode, when a tuple
arrives at the stream data processing engine, the system time of the
server on which Streaming Data Platform is running is assigned to the
tuple.
standard adaptor
An adaptor provided by Streaming Data Platform. Standard adaptors can
handle files or HTTP packets as input data, and they can output the
processing results to a file.
stream
Data that is in a streaming (time sequence) format. Stream data that
passes through an input stream queue is called an input stream, and
stream data that passes through an output stream queue is called an
output stream.
stream data
Large quantities of time-sequenced data that is continuously generated.
stream data processing engine
The part of a stream data processing system that actually processes
stream data, as instructed by queries.
stream operation
An operation that specifies how to output data in an output relation.
stream queue
A path used for input and output of stream data. A stream queue that is
used as input to the stream data processing engine is called an input
stream queue, and a stream queue that is used as output from the
stream data processing engine is called an output stream queue.
Stream to stream operations
An operation that converts stream data from one data stream to another
by performing the operation directly on the stream data without creating
a relation.
To use stream to stream operations, it is necessary to define the stream
to stream functions with CQL and create external definition functions.
time division function
A function by which a RANGE window is partitioned into desired units of
time (meshing), and the data in each of these partitioned time units is
processed separately.
timestamp
The data time in a tuple.
4 Glossary
Hitachi Streaming Data Platform

tuple
A stream data element that consists of a combination of values and time
(timestamp).
window
A range that specifies the extent of stream data that is to be
summarized and analyzed. Windows are defined in queries.
window operation
An operation used to specify a window. Window operations are coded in
CQL queries.
Glossary 5
Hitachi Streaming Data Platform

6 Glossary
Hitachi Streaming Data Platform

Hitachi Streaming Data Platform

