
Eliciting People’s First-Order Concerns:
Text Analysis of Open-Ended Survey Questions
By Beatrice Ferrario and Stefanie Stantcheva
∗
Surveys are a key tool for understanding
people’s views on public policies. They let
us slip into people’s minds and reveal other-
wise invisible things such as attitudes, per-
ceptions, reasonings, and beliefs. They can
shed light on how people reason about im-
portant policies that shape their daily lives,
such as health care, taxation, and trade pol-
icy. What efficiency and distributional im-
pacts do people have in mind when thinking
about these policies? What are their per-
ceived goals and social objectives?
To some extent, we can learn about sup-
port for some policies by observing citizens’
political behaviors. Yet, we lack data on
their more detailed policy preferences since
voting rarely happens on specific and sep-
arate issues. Furthermore, it is difficult to
infer the reasoning underlying people’s pol-
icy views using observational data. Survey
methods are thus an invaluable complement
to our other research methods.
The backbone of surveys often consists
of closed-ended questions that provide a
fixed set of answer options. The advantages
of these questions are that answer options
are standardized and streamlined across
respondents and they easily lend them-
selves to quantitative analysis. However, in
some settings, we may prime respondents
to think about (and, subsequently, perhaps
select) answer options that they would oth-
erwise not have thought about. Conversely,
we may omit relevant options that we do
not know about. In open-ended questions,
respondents are not offered answer options,
but rather, an empty text entry field in
∗
Ferrario: Harvard University, 1805 Cambridge
Street, Cambridge, MA 02138 (e-mail: beat-
rice
ing author): Harvard University, CEPR, and NBER,
1805 Cambridge Street, Cambridge, MA 02138 (e-mail:
Pezold and Martha Fiehn for exceptional research
assistance.
which they can write freely. Open-ended
survey questions can therefore circumvent
some of the above-mentioned issues. By be-
ing less guided, they may teach us things
that we may otherwise have missed and
that we may not be used to thinking about
as economists. The answers to these open-
ended questions can be analyzed using text
analysis methods to shed light on the first-
order considerations that come to people’s
minds without constraining them to think
about a limited set of answer options.
This paper illustrates the design and use
of open-ended survey questions, focusing
on the topics of income and estate taxation.
An abundant literature leverages sur-
vey data to explore people’s perceptions
and preferences about tax policy and
redistribution (Gimpelson and Treisman,
2018; Alesina, Stantcheva and Teso, 2018;
Stantcheva, 2021; Fisman et al., 2020;
Cruces, Perez-Truglia and Tetaz, 2013;
Karadja, Mollerstrom and Seim, 2017; Roth
and Wohlfart, 2018; Hvidberg, Kreiner and
Stantcheva, 2020). Perceptions (and mis-
perceptions) of tax rates are documented
in De Bartolome (1995), Gideon (2017),
Ballard and Gupta (2018), Rees-Jones
and Taubinsky (2019), Chetty, Friedman
and Saez (2013), Feldman, Katuˇsˇc´ak and
Kawano (2016), and Stantcheva (2021).
Text analysis methods of non-survey
data, such as online media and newspa-
per coverage, have been applied in finance
(Antweiler and Frank, 2004), macroeco-
nomics (Baker, Bloom and Davis, 2016),
and political economy (Groseclose and Mi-
lyo, 2005; Gentzkow and Shapiro, 2010; Te-
sei, Durante and Pinotti, 2018; Gentzkow,
Kelly and Taddy, 2019). Our goal is to
apply text analysis methods to data de-
rived from answers to open-ended survey
questions. A few papers in political sci-
1
2 PAPERS AND PROCEEDINGS MONTH YEAR
ence (Roberts et al., 2014; Brugidou, 2003)
leverage open-ended survey questions, and
the practice is also starting to spread to
economics (Stantcheva, 2020; Houde and
Wekhof, 2021).
The data for this paper comes from two
surveys on income and estate taxes, con-
ducted in 2019 on 5140 U.S. residents aged
18 to 70. The sample is representative
of the U.S. population along the dimen-
sion of gender, age, income, political af-
filiation, and employment (see Appendix
OA-1). Section I presents the application
of text analysis to open-ended survey ques-
tions. Section II summarizes key results
about people’s views on income and estate
taxation.
I. Using Open-Ended Survey Questions
A. What do Open-ended Questions Measure?
Open-ended questions can go from broad
to narrow. Broader open-ended questions
are useful to elicit first-order, intrinsic con-
cerns that people have before they are
prompted to think of a particular policy as-
pect with more directed questions. Thus, it
makes sense to start by asking people big
picture questions such as the “main consid-
erations” that come to their minds when
they think about an issue (e.g., the income
or estate tax). In our application, we then
narrow the focus by asking people what
a “good” tax system means to them and
what its goals should be, as well as what
their main perceived shortcomings of the
current U.S. tax system are. Finally, one
can ask targeted questions, such as about
the effects on the U.S. economy and on dif-
ferent groups of people if the policy were
changed (e.g., “What would be the effects
on the economy if taxes on high earners
were raised?”).
1
Ideally, open-ended ques-
tions should be complemented with closed-
ended questions for cross-validation.
It is useful to think about what the
answers to open-ended questions capture.
The answers of respondents who have
1
Appendix Section OA-2 provides all the questions
asked.
not previously thought carefully about the
topic may be “gut reactions.” These reac-
tions are informative, as they reflect what
a respondent thinks and will keep think-
ing, absent more learning or targeted re-
flection. The answers of respondents who
have already thought about the topic pre-
viously or take time to think about it dur-
ing the survey before answering may reflect
more profound views.
2
Either way, answers
to open-ended questions capture the first-
order considerations that matter to people
and the aspects of an issue that are top of
mind for them.
B. Text Analysis Methods for Open-Ended
Questions
Data pre-processing
To prepare the data for text analysis, we
first parse the answers to reduce the number
of distinct text elements. We remove punc-
tuation, excess spaces, numbers, misspelled
words, and so-called “stop words,” which
are common words that carry no intrinsic
meaning such as “and” or “the.” The re-
maining words in each answer are then lem-
matized to group all inflected forms of a
word.
3
Words appearing in the question it-
self or that occur generically in answers can
also be removed (e.g., “think,” “believe,”
and “should”). Appendix OA-4 describes
the data pre-processing in detail. We now
briefly present three text analysis methods,
with more details in Appendix OA-5.
Word Clouds
For each of the methods presented, a de-
cision has to be made on the basic unit of
analysis, i.e., the size of word groups that
will be considered as a set. “N-grams” are
groups of n words. In word clouds, the font
size for each n-gram is proportional to its
frequency. Word clouds are best used as
a first step in visualizing the data and for
scanning answers quickly. Their weakness
2
The time spent on each question can be measured
and thus, it is possible to distinguish between these two
types of responses.
3
For instance, “policies” becomes “policy,” “were”
becomes “be.”
VOL. VOL NO. ISSUE PEOPLE’S FIRST-ORDER CONCERNS ON TAX POLICY 3
is that they do not account for synonyms.
Hence, topics for which there are many pos-
sible words to express the same thought
may be artificially diluted, while niche top-
ics that feature clear buzzwords may be in-
flated in importance.
Keyness analysis
Keyness analysis is based on a relative
frequency analysis that compares the use
of n-grams between two groups (a reference
and a target/study group). The keyness
scores of an n-gram are based on the χ
2
test statistic for the null hypothesis that the
propensity to use the n-gram is the same for
the reference and target groups. In a nut-
shell, the keyness score of a term measures
how characteristic this term is of the refer-
ence group. Words that are common, but
used relatively equally by the two groups do
not have a high keyness score.
Topic Analysis
The topic analysis is based on a
keywords-count model. Topics are defined
by sets of keywords. To extract the top-
ics and associated keywords, approaches
range from manual to semi-supervised or
unsupervised (see Appendix ?? for a sum-
mary of some key methods). Many of these
methods are developed for longer text and
are not that well-suited for survey answers
which are shorter in length. In practice,
given the manageable sample sizes, a more
guided approach does better. We recom-
mend extracting the “document-term ma-
trix” (matrix of frequencies of terms in each
answer), plotting the distributions of words,
and checking many sample answers to bet-
ter understand how words are used by re-
spondents. Oftentimes, themes and com-
monly used words appear quite clearly from
the frequency distributions. It is, however,
important to do sensitivity checks on the
topics delineated and on the keywords in-
cluded. Among other decisions that need
to be made (and which warrant sensitiv-
ity analysis) are whether to count a topic
that is mentioned multiple times by a re-
spondent only once or not, and whether
to filter out differences in answer lengths
across groups by computing topic distribu-
tions within groups.
II. Application: How Do People Think
About Taxes?
To apply these methods to how peo-
ple think about income and estate taxa-
tion, we focus on answers to the broad
question “What are your main considera-
tions?” when thinking about income or es-
tate taxes, respectively. The other open-
ended questions are analyzed in Appendix
OA-8. Figure 1 shows the word clouds de-
rived from the responses. For the income
tax, respondents express disagreement with
the current levels of taxes and views on the
direction in which to change them (“lower
(a) Income Tax
lower tax
higher tax
middle class
fair share
lower class
fair tax
working class
flat tax
tax people
people higher
lower people
higher higher
tax higher
lower middle
tax class
tax middle
class people
rich people
tax tax
rich tax
rich poor
upper class
higher lower
tax lower
people work
double tax
government spending
everyone fair
middle lower
people tax
tax good
everyone share
wealthy tax
tax high
higher people
government spend
work hard
cant afford
family tax
tax everyone
end meet
social security
working people
tax share
wealthy fair
national debt
people lower
poor people
tax wealthy
class class
class higher
people rich
higher class
across board
rich fair
government waste
lower government
higher wealthy
lower working
people spend
poor rich
very high
tax break
people people
class rich
rich rich
sales tax
higher rich
people afford
social program
high earner
class tax
tax government
wealthy people
lower lower
higher earner
tax poor
people high
poor class
tax rich
class poor
rich share
people struggle
universal healthcare
tax fair
take home
class middle
lower higher
people government
government good
people hard
tax level
good people
class upper
tax working
capital gain
many people
rich higher
everyone tax
middle people
very rich
people back
people cant
people fair
wealthy share
progressive tax
middle working
lower family
working middle
class lower
higher middle
level tax
lower good
tax economy
people take
take paycheck
high people
government control
nothing come
take away
tax benefit
wealthy higher
economic growth
close loophole
government program
good job
tax loophole
fair everyone
american people
paycheck paycheck
fair people
poor middle
support government
long term
hard people
tax always
people keep
government people
standard deduction
class too much
higher everyone
whether tax
hard earn
class fair
affect economy
two thousand
tax across
fund government
higher level
spend economy
class family
middle poor
people earn
working poor
government take
good economy
higher good
loophole wealthy
higher afford
tax low
poor lower
affect personally
take check
middle higher
upper middle
business business
affect family
fair rich
poor poor
hard working
double high
favor tax
president trump
poverty level
higher earn
everyone government
afford higher
tax afford
tax business
people working
government provide
low people
minimum wage
fifty thousand
working citizen
economy government
tax spend
many loophole
loophole rich
government fund
lower everyone
high low
different class
ten million
hundred thousand
break rich
class big
raise lowering
break working
people break
(b) Estate Tax
double tax
fair tax
middle class
family tax
lower class
lower tax
work hard
tax tax
tax twice
lower income
tax no tax
tax bracket
tax double
working class
income tax
higher lower
tax government
tax free
income bracket
government tax
lower family
fair share
higher income
government right
tax income
five million
cant afford
hundred thousand
wealthy tax
work life
low income
higher tax
tax higher
income family
transfer tax
upper class
tax high
tax transfer
family farm
left behind
higher rich
two thousand
higher higher
rich poor
good way
family government
lower high
tax time
cost live
wealthy family
way government
rich rich
lower higher
likely tax
middle lower
higher little
tax fair
rich tax
lower inherit
small business
wealthy higher
higher bracket
government family
afford higher
tax lower
family family
lower lower
tax inherit
ten million
since tax
income inherit
class lower
poor class
lower middle
family without
inherit tax
higher wealthy
lower government
capital gain
financial burden
tax way
transfer fund
bracket higher
save tax
family no tax
poor rich
burden family
hard work
asset tax
lower good
flat tax
family business
higher class
tax impose
lower work
lower poor
high income
tax asset
transfer higher
fair inherit
tax good
tax live
lower way
way lower
next generation
hard life
lose lovedone
little higher
whole life
slide scale
government transfer
first place
higher way
hard tax
ultra wealthy
tax died
income level
class family
entire life
wealthy fair
income income
rich higher
either way
hard family
wealthy income
lower since
high tax
no tax government
government revenue
financial situation
inherit large
hard save
lower burden
tax previously
life insurance
tax save
lower bracket
family generation
lower hard
lower afford
low family
tax wealthy
lowered tax
lower fair
government greedy
lower lose
large sum
tax since
exist tax
government double
lower no tax
no tax tax
government no tax
work save
class poor
belong family
life government
good government
eliminate tax
tax fund
family good
class afford
higher middle
higher transfer
work child
family work
owner tax
benefit wealthy
life work
farm business
work tax
work family
Figure 1. : Main Considerations about In-
come and Estate Taxes
Note: Word clouds based answers to open-ended
question about respondents’ main considerations about
income and estate taxes.

4 PAPERS AND PROCEEDINGS MONTH YEAR
tax” or “higher tax,” depending on the
groups they refer to) and concern about the
impacts on the “middle class.” For the es-
tate tax, respondents’ first-order reaction
centers around “double taxation” and the
fairness of the estate tax, followed closely
by concerns about the “middle class” and
“family.”
A. Key topics mentioned
Figure 2 shows the distribution of top-
ics in respondents’ answers by political af-
filiation. For the income tax, there are
eight distinct topics: Distribution, Fair-
ness, Government Spending, Social Insur-
ance, Efficiency, Loopholes, Flat Tax, Pub-
lic Goods, and Don’t Know (the labels are
chosen by us and need not be words used by
respondents). For instance, the Distribu-
tion topic contains keywords such as “mid-
dle class,” “low income, “millionaire.” The
Fairness issue contains the words “fair” and
“unfair.” Public Goods captures “infras-
tructure,” “education,” and “health care.”
Efficiency is represented by words such as
“hurt economy,” “work less,” “competi-
tion,” and “spend less,” among others. The
final category is for respondents who ex-
press that they do not know enough about
the policy to give a meaningful answer.
Appendix OA-6 lists the full set of key-
words identifying each topic, and example
answers are in Appendix OA-7. An answer
is counted as mentioning a topic if it con-
tains at least one of the topic keywords. An-
swers can thus contain multiple topics.
The topics of Distribution and Fairness,
as well as Government Spending and Loop-
holes are most frequently mentioned. The
Efficiency topic does not appear to be top
of mind for most people. These results
echo Stantcheva (2021), which uses a finer
a finer decomposition analysis that lever-
ages a series of (non open-ended) survey
questions. The paper finds that distribu-
tional and fairness considerations dominate
efficiency concerns in shaping people’s tax
policy views. Thus, people’s responses to
the open-ended questions already provide
meaningful insights into what matters to
them.
(a) Income Tax
0
10
20
30
40
50
Distribution
0
10
20
30
40
50
Fairness
0
10
20
30
40
50
Gov. Spending
0
10
20
30
40
50
Social Safety
0
10
20
30
40
50
Efficiency
0
10
20
30
40
50
Flat Tax
0
10
20
30
40
50
Loopholes
0
10
20
30
40
50
Public Goods
0
10
20
30
40
50
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
(b) Estate Tax
0
10
20
30
40
50
Distribution
0
10
20
30
40
50
Fairness
0
10
20
30
40
50
Gov. Spending
0
10
20
30
40
50
Efficiency
0
10
20
30
40
50
Loopholes
0
10
20
30
40
50
Double Tax
0
10
20
30
40
50
Grieve
0
10
20
30
40
50
Public Goods
0
10
20
30
40
50
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
Figure 2. : Main Topics Respondents think
About Regarding the Income and Estate
Tax by Political Affiliation
Note: The figure shows distribution of topics mentioned
in the answers about main considerations about income
and estate taxes. The bars represent the number of
times a topic was mentioned out of the total mentions
of any topic by political group.
For the estate tax in Panel B, the top-
ics are similar to those from the income
tax survey. Specific to the estate tax is
the Double Tax topic, captured by key-
words such as “already taxed,” “already
paid,” and “taxed/paid twice” and the
Grieve topic, which is captured by terms
such as “grieve,” “bury,” and “funeral.”
The distribution of topics is again heav-
ily centered around issues of Distribution
and Fairness, but Double Tax also carries
a lot of weight. Much rarer are mentions
of Government Spending, Efficiency, Loop-
holes, Grieve, and Public Goods. Further-
more, more people express a lack of knowl-
edge about the estate tax than the income
tax.
B. Political differences in topics mentioned
It is useful to plot topic distributions for
different groups to see whether first-order
concerns are heterogeneous across respon-
dents. Figure 2 does this by political affilia-
tion, while Appendix OA-8 provides cuts by
age, income, and education groups. Politi-

VOL. VOL NO. ISSUE PEOPLE’S FIRST-ORDER CONCERNS ON TAX POLICY 5
cal leanings are captured by both the vote
in 2016 (Clinton vs. Trump) and by a self-
reported degree of conservatism vs. liberal-
ism (see Appendix OA-3 for details). The
four main categories that emerge are: Clin-
ton Liberals, Clinton Moderates, Trump
Moderates, and Trump Conservatives.
There are clear political differences in the
topics mentioned. Issues related to Dis-
tribution are much more prevalent on the
left side of the political spectrum than on
the right: they represent 50% of topics
mentioned by Clinton Liberals and 25% by
Trump Conservatives. Government spend-
ing, on the other hand, is a more pressing
concern for respondents on the right, ac-
counting for less than 4% of topic mentions
for Clinton Liberals and 22% for Trump
Conservatives. Efficiency is not frequently
mentioned by any political group. Fair-
ness mentions are quite evenly distributed
across the political spectrum. However,
even though everyone cares about fair-
ness, the meaning of this concept greatly
differs across respondents: fairness is in
the eye of the beholder. The answers
to this broad open-ended question thus
prompt us to ask more detailed (open-
and closed-ended) questions about fairness
(Stantcheva, 2021).
Figure 3 shows the keywords that are
most specific to Democrats and Repub-
licans. Consistent with the topic distri-
bution, the keywords on the Democrat
side center around issues of Distribution
(“poor rich,” “lower class,” “middle class,”
and “tax wealthy”). Republicans tend
to emphasize Government Spending, Gov-
ernment Waste, and the Economic Costs
(“people work,” “economy spend”).
For the estate tax, there are also clear dif-
ferences in the topics mentioned by politi-
cal leanings. Distribution issues are most
prevalent among Clinton Liberals and di-
minish rapidly and monotonically towards
Trump Conservatives. Conversely, Dou-
ble Taxation concerns are prevalent among
Trump Conservatives, but quite rare among
Clinton Liberals. The mentions of Fairness
are again evenly distributed across the po-
litical spectrum. These patterns are con-
firmed by the keyness analysis (Panel B of
Figure 3).
Figure OA-2 shows the distribution of re-
sponses to the question “Who gains if taxes
on high earners were increased?” Among
Democrats, prevalent answers are “the mid-
dle class” and “everybody.” Among Repub-
(a) Income Tax
higher middle *
poor class *
working class *
not fair **
upper class **
higher class **
tax wealthy **
lower middle **
higher rich **
tax middle **
higher wealthy ***
fair share ***
higher earner ***
rich people ***
tax class ***
fair rich ***
higher tax ***
lower class ***
higher people ***
poor rich ***
middle class ***
government waste ***
government spending ***
economy spend ***
government lower ***
flat tax ***
people work **
lower tax *
live paycheck *
−10
0
10
20
30
Considerations
Chi2
Democrat Republican
(b) Estate Tax
class working *
income bracket **
lower class **
middle class ***
already tax ***
family government ***
hard work ***
family tax ***
tax twice ***
double tax ***
already no tax ***
income tax **
already lower *
−75
−50
−25
0
25
Considerations
Chi2
Democrat Republican
Figure 3. : Keywords Mentioned by
Democrats and Republicans Regarding the
Income and Estate Tax
Note: The figure shows keywords among Democrats and
Republicans in answers to the question about respon-
dents’ main considerations on the income and estate
taxes. The score reported for a set of two words is
the χ
2
- test statistic, testing the null hypothesis that
the occurrence of the given keywords is the same among
Democrats and Republicans. * p ă 0.1, ** p ă 0.05,
*** p ă 0.01. See Appendix OA-5.2.
6 PAPERS AND PROCEEDINGS MONTH YEAR
licans, common answers are “nobody” and
“government and politicians.” This shows
that beliefs in “trickle-down” economics are
more prevalent on the right. Figure OA-6
shows similar perceived winners and losers
from estate tax increases.
On the perceived shortcomings of the in-
come tax, Figure OA-3 shows that key-
words specific to Democrats relate to Loop-
holes and Tax Breaks for the Rich and Cor-
porations, while for Republicans they cen-
ter around Government Spending and Work
(i.e., that taxes discourage work and that it
is unfair to tax hard-working people).
III. Conclusion
Open-ended survey questions offer the
potential to elicit people’s first-order con-
siderations on policy issues. By not con-
straining respondents to a given set of
answer choices, they avoid priming them
to think of otherwise non-salient options
or omitting relevant options. Open-ended
questions can range from broader to more
targeted. Leveraging recent advances in
text analysis, their answers can be visual-
ized and quantitatively studied to shed light
across many areas of economics.
REFERENCES
Alesina, Alberto, Stefanie Stantcheva, and
Edoardo Teso. 2018. “Intergenerational mobil-
ity and preferences for redistribution.” American
Economic Review, 108(2): 521–54.
Antweiler, Werner, and Murray Z. Frank.
2004. “Is All That Talk Just Noise? The In-
formation Content of Internet Stock Message
Boards.” The Journal of Finance, 59(3): 1259–
1294.
Baker, Scott R, Nicholas Bloom, and
Steven J Davis. 2016. “Measuring economic
policy uncertainty.” The Quarterly Journal of
Economics, 131(4): 1593–1636.
Ballard, Charles L, and Sanjay Gupta. 2018.
“Perceptions and realities of average tax rates
in the federal income tax: evidence from Michi-
gan.” National Tax Journal, 71(2): 263–294.
Brugidou, Mathieu. 2003. “Argumentation and
Values: an analysis of ordinary political compe-
tence via an open-ended question.” International
Journal of Public Opinion Research, 15(4): 413–
430.
Chetty, Raj, John N Friedman, and Em-
manuel Saez. 2013. “Using Differences in
Knowledge across Neighborhoods to Uncover the
Impacts of the EITC on Earnings.” American
Economic Review, 103(7): 2683–2721.
Cruces, Guillermo, Ricardo Perez-Truglia,
and Martin Tetaz. 2013. “Biased Perceptions
of Income Distribution and Preferences for Re-
distribution: Evidence from a Survey Experi-
ment.” Journal of Public Economics, 98(C): 100–
112.
De Bartolome, Charles AM. 1995. “Which tax
rate do people use: Average or marginal?” Jour-
nal of Public Economics, 56(1): 79–96.
Feldman, Naomi E, Peter Katuˇsˇc´ak, and
Laura Kawano. 2016. “Taxpayer confusion:
Evidence from the child tax credit.” American
Economic Review, 106(3): 807–35.
Fisman, Raymond, Keith Gladstone, Ilyana
Kuziemko, and Suresh Naidu. 2020. “Do
americans want to tax wealth? evidence from
online surveys.” Journal of Public Economics,
188: 104207.
Gentzkow, Matthew, and Jesse M Shapiro.
2010. “What drives media slant? Evidence from
US daily newspapers.” Econometrica, 78(1): 35–
71.
Gentzkow, Matthew, Bryan Kelly, and Matt
Taddy. 2019. “Text as Data.” Journal of Eco-
nomic Literature, 57(3): 535–74.
Gideon, Michael. 2017. “Do Individuals Perceive
Income Tax Rates Correctly?” Public Finance
Review, 45(1): 97–117.
Gimpelson, Vladimir, and Daniel Treisman.
2018. “Misperceiving inequality.” Economics &
Politics, 30(1): 27–54.
Groseclose, Tim, and Jeffrey Milyo. 2005. “A
measure of media bias.” The Quarterly Journal
of Economics, 120(4): 1191–1237.
Houde, S´ebastien, and Tobias Wekhof. 2021.
“The narrative of the energy efficiency gap.”
Economics Working Paper Series, 21.
Hvidberg, Kristoffer, Claus Kreiner, and
Stefanie Stantcheva. 2020. “Social Position
and Fairness Views.” NBER Working Paper
28099.
Karadja, Mounir, Johanna Mollerstrom, and
David Seim. 2017. “Richer (and Holier) than
Thou? The Effect of Relative Income Improve-
ments on Demand for Redistribution.” Review of
Economics and Statistics, 99(2): 201–212.
Rees-Jones, Alex, and Dmitry Taubinsky.
2019. “Measuring “Schmeduling”.” The Review
of Economic Studies, 87(5): 2399–2438.
Roberts, Margaret E, Brandon M Stewart,
Dustin Tingley, Christopher Lucas, Jet-
son Leder-Luis, Shana Kushner Gadarian,
Bethany Albertson, and David G Rand.
2014. “Structural topic models for open-ended
survey responses.” American Journal of Politi-
cal Science, 58(4): 1064–1082.
Roth, Christopher, and Johannes Wohl-
fart. 2018. “Experienced Inequality and Prefer-
ences for Redistribution.” Journal of Public Eco-
nomics, 167: 251–262.
Stantcheva, Stefanie. 2020. “Understanding Eco-
nomic Policies: What Do People Know and How
Can They Learn?” Harvard University Working
Paper.
Stantcheva, Stefanie. 2021. “Understanding tax
policy: How do people reason?” The Quarterly
Journal of Economics, 136(4): 2309–2369.
Tesei, A, R Durante, and P Pinotti. 2018.
“The Political Legacy of Entertainment TV.”
American Economic Review.
ONLINE APPENDIX
for “Eliciting People’s First-Order Concerns:
Text Analysis of Open-Ended Survey Questions”
by Beatrice Ferrario and Stefanie Stantcheva
Contents
OA-1 Representativeness of the Sample . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-2
OA-2 Open-ended Questions Wording . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-3
OA-3 Political Affiliation Categories . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-3
OA-4 Preprocessing Steps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-5
OA-4.1 Word clouds and Keyness Graphs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-5
OA-4.2 Topic Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-5
OA-5 Methods . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-6
OA-5.1 Word clouds . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-6
OA-5.2 Keyness and keyword graphs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-6
OA-5.3 Topic analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-7
OA-6 Topic Keywords . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-8
OA-7 Sample of Answers to the Open-ended Question “What are your Main Considerations about
the Policy?” . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-9
OA-7.1 Income Taxation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-9
OA-7.2 Estate Tax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-10
OA-8 Additional Figures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-11
List of Figures
OA-1 Word clouds for the Income Tax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-11
OA-2 Distributional effects of Income Tax Increase: Who Gains if Taxes on High Earners were to
be Increased? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-13
OA-3 Keywords of Income Taxation by Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-14
OA-4 Word clouds for the Estate Tax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-16
OA-5 Keywords of Estate Tax by Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-17
OA-6 Distributional effects of Estate Tax Increase: Who Loses if the Estate Tax were Increased? OA-19
OA-7 Probability of Mentioning Topics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . OA-20
OA-8 Topic Distribution by Political Affiliation for the Income Tax . . . . . . . . . . . . . . . . . . OA-22
OA-9 Topic Distribution by Income Groups for the Income Tax . . . . . . . . . . . . . . . . . . . OA-23
OA-10 Topic Distribution by Age Group for the Income Tax . . . . . . . . . . . . . . . . . . . . . . OA-24
OA-11 Topic Distribution by Political Affiliation of the Estate Tax . . . . . . . . . . . . . . . . . . OA-25
OA-12 Topic Distribution by Income Groups of the Estate Tax . . . . . . . . . . . . . . . . . . . . OA-26
OA-13 Topic Distribution by Age Group of the Estate Tax . . . . . . . . . . . . . . . . . . . . . . . OA-27
OA-1

OA-1 Representativeness of the Sample
For more details on the surveys, sample, data collection, and data analysis, see Stantcheva (2021). The full
questionnaire is in Section OA-2 of the Online Appendix of that paper.
Table OA-1: Sample Characteristics
US Population Income Tax Survey Estate Tax Survey
Male 0.49 0.48 0.46
18-29 years old 0.24 0.23 0.22
30-39 years old 0.20 0.20 0.20
40-49 years old 0.18 0.19 0.19
50-59 years old 0.19 0.21 0.19
60-69 years old 0.19 0.18 0.19
$0-$19,999 0.13 0.15 0.16
$20,000-$39,999 0.16 0.19 0.19
$40,000-$69,999 0.21 0.23 0.24
$70,000-$109,999 0.20 0.19 0.19
$110,000+ 0.31 0.24 0.20
Four-year college degree or more 0.34 0.48 0.46
High-school graduate or less 0.38 0.19 0.19
Employed 0.70 0.63 0.62
Unemployed 0.03 0.07 0.06
Self-employed 0.07 0.07 0.06
Married 0.53 0.55 0.53
White 0.61 0.76 0.76
Black/African-American 0.12 0.06 0.06
Hispanic/Latino 0.18 0.06 0.07
Asian/Asian-American 0.06 0.07 0.07
Democrat 0.30 0.34 0.35
Republican 0.26 0.31 0.30
Independent 0.42 0.33 0.33
Voted for Clinton in the 2016 Presidential Election 0.48 0.44 0.44
Voted for Trump in the 2016 Presidential Election 0.46 0.44 0.44
Sample size 2784 2360
Notes: This table displays statistics for the overall US population (column 1) and compares it to the characteristics of the
samples of the income tax and estate tax surveys (columns 2 and 3). National statistics on gender, age, income brackets, race,
education, marital status, and employment status are from the IPUMS-CPS-ASEC dataset for March 2019 (Flood et al., 2020).
National statistics on party affiliation for March 2019 are from Gallup (2019). Statistics on 2016 Presidential Election Results
are from Leip (2019). See Stantcheva (2021) for details on how the summary statistics are constructed.
OA-2
OA-2 Open-ended Questions Wording
This section provides the open-ended questions that were asked to respondents in the surveys. See Stantcheva
(2021) for the full questionnaires.
We now want to ask you a few broader questions. Please use the text boxes below and write as much as you
feel like. Your opinion and thoughts are important to us! There is no right or wrong answer.
Income Taxation Survey
1. When you think about federal personal income taxation and whether the U.S. should have higher or
lower federal personal income taxes, what are the main considerations that come to your mind?
2. What would be a “good” federal tax system in your view? What would be the goal of a good tax system?
3. What do you think are the issues with or shortcomings of the U.S. federal income tax system?
4. Which important aspects of the U.S. federal income tax system would you say are not discussed enough
in the current policy debate?
5. What do you think would be the effects on the U.S. economy if the federal personal income taxes were
increased?
6. Which groups of people do you think would gain if federal personal income taxes on high earners were
increased?
7. Which groups of people do you think would lose if federal personal income taxes on high earners were
increased?
Estate Tax Survey
1. The federal estate tax is a tax imposed on the transfer of wealth from a deceased person to his or her
heirs. When you think about the federal estate tax and whether the U.S. should have a higher or a
lower federal estate tax, what are the main considerations that come to your mind?
2. In your view, what would be a “good” federal estate tax that you would be satisfied with? What would
be the goal of a good estate tax system?
3. What do you think are the shortcomings of the U.S. federal estate tax?
4. What do you think would be the effects on the U.S. economy if the federal estate tax were increased?
5. Which groups of people do you think would gain if the federal estate tax were increased?
6. Which groups of people do you think would lose if the federal estate tax were increased?
OA-3 Political Affiliation Categories
This section reports the questions that we used to construct the political categories of Figure 3, the definition
of political categories, summary statistics of the political leanings in the sample.
1. Did you vote in the last presidential election?
Yes; No
2. (If “Yes” to 1) In the last presidential election, supported:
Hillary Clinton; Donald Trump; Jill Stein; Gary Johnson; Other
(If “No” to 1) Even if you did NOT vote, please indicate the candidate that you were most likely to
have voted for or who represents your views more closely.
Hillary Clinton; Donald Trump; Jill Stein; Gary Johnson; Other
OA-3

3. On economic policy matters, where do you see yourself on the liberal/conservative spectrum? Very
liberal; Liberal; Moderate; Conservative; Very conservative
Definition of Variables:
Trump Conservative: respondent supported Donald Trump in the 2016 presidential elections and has
“conservative” or “very conservative” views on economic policy matters.
Trump Moderate: respondent supported Donald Trump in the 2016 presidential elections and has
“moderate” views on economic policy matters.
Clinton Moderate: respondent supported Hillary Clinton in the 2016 presidential elections and has
“moderate” views on economic policy matters.
Clinton Liberal: respondent supported Hillary Clinton in the 2016 presidential elections and has “lib-
eral” or “very liberal” views on economic policy matters.
Table OA-2: Political Affiliation and Views on Economic Policy Matters
in the Income Tax Survey
D. Trump H. Clinton G. Johnson J. Stein Other
Liberal 7% 54% 12% 53% 15% 29%
Moderate 32% 38% 62% 37% 57% 39%
Conservative 61% 7% 26% 10% 28% 32%
Total 100% 100% 100% 100% 100% 100%
Notes: The table shows the distribution of the respondents’ views on economic policy matters by political candidate supported
in the 2016 presidential elections in the income tax survey sample.
Table OA-3: Political Affiliation and Views on Economic Policy Matters
in the Estate Tax Survey
D. Trump H. Clinton G. Johnson J. Stein Other
Liberal 8% 55% 16% 43% 19% 30%
Moderate 31% 38% 54% 45% 58% 38%
Conservative 61% 7% 31% 12% 23% 32%
Total 100% 100% 100% 100% 100% 100%
Notes: The table shows the distribution of the respondents’ views on economic policy matters by political candidate supported
in the 2016 presidential elections in the estate tax survey sample.
OA-4
OA-4 Preprocessing Steps
This section summarizes the preprocessing steps performed to carry out the text analysis. The first step,
whose goal is to reduce the number of distinct elements, is common to all three methods, whereas the
subsequent steps are specific to each of the methods.
Given an answer d
i
:
1. Parse d
i
: lower-case every word, remove punctuation, spaces in excess, numbers, misspelled words, very
common words that carry no intrinsic meaning (“stopwords”) such as “and,” “the,” “each,” “then”.
OA-4.1 Word clouds and Keyness Graphs
2. Lemmatizing remaining words, i.e. grouping together the inflected forms of a word so they can be
analysed as a single item.
– Use the English lemmatization list available in the lexicon package.
– e.g., : “policies” becomes policy, “were” becomes “be” → reduces number of distinct textual
elements
→ Output: (
ˆ
d
i
)
3. Remove words coming from the question as well as extra words related to the structure of answer.
– e.g., for the question, “what are your main considerations about income tax system?” : remove
“main,” “considerations,” “income,” from the answers, as well as “think,” “believe,” “should,”
etc.
4. Transform
ˆ
d
i
into numerical vector c
i
in which each element is a 2-gram, i.e. a 2-component expression
of two words which were separated by 0 or 1 word in the original text. Group together 2-grams which
correspond to the same inverted two words. Manually remove 2-grams which have no grammatical
foundation and duplicated 2-grams (e.g., “tax tax”).
– e.g., take d
1
= “We should tax the wealthy more and tax the poor less.” After steps 1-2-3 becomes:
ˆ
d
i
= “tax wealthy more tax poor less”. After step 4 becomes: [‘tax wealthy’ = 1, ‘tax more’ = 2,
‘wealthy more’ = 0 (because it is not grammatically coherent), ‘tax poor’ = 1, ‘poor people’ = 0,
...]
OA-4.2 Topic Analysis
2. Reduce remaining words to common root (stemming).
– Use Snowball stemming algorithm
– policies and policy become polic → reduces number of distinct textual elements.
→ Output: (
ˆ
d
i
)
3. Transform
ˆ
d
i
into numerical vector c
i
in which each element is the count of a distinct word.
– e.g., take d
1
= “We should tax the wealthy more and the poor less.”
∗ After Steps 1-2 becomes:
ˆ
d
1
= “tax wealthi more poor less”
∗ After Step 3 becomes: [‘tax’ = 1, ‘wealthi’ = 1, ‘more’ = 1, ‘poor’ = 1, ‘less’ = 1 ...]
4. Generate topic dummy variables equal to 1 when an element of c
i
matches a custom-made topic
dictionary.
OA-5

OA-5 Methods
OA-5.1 Word clouds
The simplest text analysis consists in plotting “word clouds,” which are based on a frequency analysis.
The frequency of each identified n-gram is computed and the feature label is plotted proportional to this
frequency. The word clouds and keyness figures are based on the package by Benoit et al. (2018). The
transparency and font size are proportional to the frequency of each group of words relative to the total.
Pros and Cons. Word clouds are a key tool for visualizing responses to open-ended survey questions. The
font size of a word group is displayed proportionally to its frequency, yielding an insightful starting point for
the analysis of text (Heimerl et al., 2014).
By clearly presenting which themes seem to be common among people’s answers, word clouds can equip
researchers with a first intuition for topics that could be fruitful to explore further. This quick assessment
of answers is particularly useful when analyzing large text corpora in the age of Big Data, or in our case, a
large number of open-ended responses to survey questions.
This approach, however, comes with certain drawbacks. For instance, word clouds do not account for
synonyms, i.e., they will fail to link only slightly different words to the same underlying idea. As a result,
themes that can be described in various ways will be less prevalent in the word cloud, while the importance
of topics that are clearly associated with certain “buzzwords” might be over-represented. Beyond that, word
clouds take the individual words out of context, potentially leading to a loss of interpretability or meaning.
Overall, word clouds are a useful way to visualize and explore textual data. It would be premature, however,
to draw any final conclusions about the importance of topics simply based on the font size of occurring
words. Instead, the themes communicated in word clouds should be seen as a first step in text analysis and
used as cautiously-interpreted guidance for further analysis.
OA-5.2 Keyness and keyword graphs
Related Literature. We draw on an in-depth overview by Gabrielatos (2018), which describes the history
of keyness analysis and provides a critical review of its applications. In addition, Stubbs (2010) digs into the
notion of “keywords,” which parallels the idea of keyness.
Among the first to conduct keyness analysis is Leech and Fallon (1992), who study the drivers of differences
between cultures by comparing corpora in American and British English. Today, keyness analysis is under-
stood primarily as a comparison of frequencies of words in the so-called study and reference groups. This
approach can be used to elicit degrees of similarity or difference between the studied groups (Gentzkow and
Shapiro, 2010; Taylor, 2013; Partington, 2014).
The keyness graphs in this paper are based on a relative frequency analysis that compares the use of n-grams
identified in the corpus between two groups (a reference and a target group). To establish the keyness score
of a given item, we establish its frequency relative to the number of words in the group corpus (i.e., the
number of words in all the answers of a given group). Those frequencies are cross-tabulated and a χ
2
test is
conducted to test the independence between the two groups’ distribution.
Consider a given n-gram i. Let j be the group index, with j = 0 for the reference group and j = 1 for
the target group. Let A
i,j
be the observed number of occurrences of the n-gram i in group j and A
−i,j
the
observed number of occurrences of all other n-grams (except the one we consider) in this group. Let R
i
be
the total number of occurrences of n-gram i in both groups, C
j
be the number of occurrences of all n-grams
in group j, and N the overall number of occurrences of n-grams in both groups.
To perform the test, we first establish the theoretical distribution under the independence hypothesis by
computing E
i,j
, the expected frequency of a given n-gram i in group j :
E
i,j
=
R
i
× C
j
N
OA-6

and the expected frequency of all other n-grams in group j:
E
−i,j
=
R
−i
× C
j
N
The χ
2
test statistic is:
χ
2
= (−1)
1{E
−i,1
>A
−i,1
}
X
k∈{−i,i}
1
X
j=0
(A
k,j
− E
k,j
)
2
E
k,j
We compare this statistic to the distribution of a χ
2
distribution law with one degree of freedom (i.e., number
of groups −1). A given n-gram is significant when the independence hypothesis is rejected and the n-gram is
considered a “keyword.” A negative χ
2
indicates that the word is significantly more frequent in the reference
group. In absolute value terms, the null hypothesis is rejected at the 10% level when |χ
2
| > 2.71 (*), at the
5% level when |χ
2
| > 3.84 (**) and at the 1% level when |χ
2
| > 6.63 (***).
Pros and Cons. Keyness analysis is particularly useful when the goal is to compare text corpora associated
with different groups. It is based on a relative frequency analysis that compares the use of words between
two groups, for example, Democrats and Republicans in our study.
This simple method allows us to compute a keyness score that measures how characteristic an n-gram is for
a given group. Based on this, keyness analysis can be used to establish differences (similarities) between
groups. It also allows the researcher to extract notions and attitudes that are at the heart of a given group’s
text corpus. Thus, this method can, for instance, help elevate our understanding of what drives polarization
within the political spectrum.
One common critique of keyness analysis is that it is based purely on statistical significance and does not
take into account the effect size (Gabrielatos and Marchi, 2011; Kilgarriff, 2001). In particular, we do not
learn about the size of a frequency difference (Gabrielatos, 2018).
Overall, keyness analysis serves as a valuable tool when the goal is to explore potential heterogeneity, e.g., in
attitudes across groups. Yet, results need to be interpreted with caution, given the limitations of the method
(Gabrielatos, 2018). Indeed, while statistical significance is a useful metric, its utility is limited to express
the accuracy of a given frequency difference. Furthermore, keyness is not an intrinsic attribute of words but
depends on several subjective decisions regarding, for instance, the size of the linguistic units that are the
focus of the analysis, the target and reference text corpora, and the statistical significance thresholds.
OA-5.3 Topic analysis
Related Literature. Topic analysis was originally developed as a tool for text mining with the goal to
impose structure on the rapidly expanding textual data on the internet (Baeza-Yates et al. (1999)). Salton
and McGill (1983) introduced a now widely-applied method that compares a normalized word frequency
count, within one document, to an inverse document frequency count within a text corpus containing all
considered documents. To reduce the dimensionality of vast text corpora, Deerwester et al. (1990) introduced
latent semantic indexing (LSI), a method later advanced by Hofmann (1999) into the probabilistic LSI (pLSI).
Another approach to topic modeling is the latent Dirichlet allocation (LDA), developed by Blei et al. (2003).
Further developments include dynamic topic models (Blei and Lafferty (2006)) and supervised topic models
(Blei and Jon (2007)). A more recent advancement was driven by Roberts et al. (2013) and Roberts et al.
(2014), who introduce structural topic models and apply the method to open-ended survey responses.
Topic analysis is a versatile tool that can be applied to a wide range of bodies of text. Like keyness anal-
ysis, it allows to study heterogeneity in topics use across groups, but its advantage is that we can also flag
topics for which the frequency of use is similar across the different groups.(Roberts et al. (2014)). For more
comprehensive reviews of the limitations of topic analysis and potential solutions, see Tang et al. (2014) and
Agrawal et al. (2018).
Semi-supervised approaches to topic modeling allow the researcher to suggest a set of words around which
the algorithm attempts to build topics. Including additional information, e.g., from external data sources,
OA-7
in the topic modeling process can significantly improve classification results. Banerjee et al. (2007) and
Sch¨onhofen (2009) draw on the titles and categories of Wikipedia articles, as an external data source, to
improve the clustering accuracy of their documents.
To improve the interpretability of topics, Lu et al. (2011) propose an algorithm that is closely related to
Latent Dirichlet Allocation (LDA). Another approach, referred to as “Newsmap” and based on naive Bayes
classifiers, was introduced by Watanabe (2018b) and implemented in Watanabe (2018a). Both the seeded-
LDA and the Newsmap models were employed in Watanabe and Zhou (2020). Finally, Gallagher et al.
(2017) develops a novel approach that does not require assumptions about the underlying data generation
process: the “Correlation Explanation” (CorEx) Topic Model.
Semi-supervised algorithms reduces the amount of hand-coding necessary by the researcher and are by na-
ture, data driven. Nevertheless, there are always decisions to be made. For instance, one needs to chose how
fine-grained or coarse to make the topics, whether to use the same keywords across time (e.g., newspaper
articles across decades) and across people (e.g., groups that may use different language), or rather adapt them.
For open-ended survey questions, it can make sense to pick topics manually, because the answers are shorter
than most of the texts that topic analysis has been used for. It is of course then possible to cross-validate
the results using less supervised methods. When topics are chosen with a more hands-on approach, multiple
hypothesis testing may become a concern Roberts et al. (2014), but could possibly be alleviated thanks to
a pre-analysis plan. In practice, we use a manual approach.
Our approach. As a first preliminary step, we extract the document-term matrix (DTM). The DTM is
a mathematical matrix that describes the frequency of terms that occur in a given set of documents (in
our case, a document coincides with the answer of a given respondent to a given question). The rows and
columns correspond to documents and terms, respectively. Hence, the element (x,y) in the DTM corresponds
to the frequency of the term y in question answer x.
Topics are then defined by sets of keywords that aim to capture the particular aspects of the policy with
which the respondent is concerned when answering to the question. We fix these topics based on the distri-
bution of words that we see in the answers (i.e., in the DTM) and on our understanding of the issues studied.
It is critically important to read many sample answers in order to better understand how respondents are
interpreting the question and how they are using specific terms. The topic indicator variable is equal to one
if the document contains at least one of the keywords that define the topic. Documents can thus contain
more than one topic if the respondent used keywords belonging to different topics.
OA-6 Topic Keywords
In this section, we provide the full list of keywords used to define the topics presented in Figure 2 and in
Figures OA-8 to OA-13 of this Online Appendix.
OA-8

Table OA-4: Keywords Defining the Income Tax Topics
Distribution: Middle class; working class; low income; wealthy; millionaire; rich; billion-
aire; corporations & pay/tax
Fairness: Fair; unfair
Government spending: Government spending & high; government spending & cut; deficit; debt;
government & waste; balance & budget; government & budget; government
& control & spend
Social insurance: Social services; governmental services; governmental program & fund; gov-
ernmental program & cover; help & poor; pay & poor; social program; poor
work; live & paycheck; provide & family
Efficiency: Hurt & economy; work hard; work less; work more; create & job; depress;
trickle down; negative/detrimental/destroy/damage & economy; competi-
tion; innovation; create & business; boost & economy; discourage; spend
less
Flat tax: Flat tax
Loopholes: Loopholes; lawyer; account; tax evasion; evade; avoid taxes
Public goods: Infrastucture; education; healthcare
Don’t know: Not know; knowledgeable enough; idk; not sure; know enough; unsure
Table OA-5: Keywords Defining the Estate Tax Topics
Distribution: Middle class; working class; low income; wealthy; millionaire; rich; billion-
aire; corporations & pay/tax; poor; inequality
Fairness: Fair; unfair
Government spending: Government spending & high; government spending & cut; deficit; debt;
government & waste; balance & budget; government & budget; government
& control & spend
Efficiency: Hurt economy; work hard; flat
Loopholes: Loopholes; lawyer; account; tax evasion; evade; avoid taxes
Double tax: Already taxed/paid; twice & tax/pay
Grieve: Grieve; bury; funeral
Public goods: Infrastructure; education; health care
Don’t know: not know; knowledgeable enough; idk; not sure; know enough; unsure
OA-7 Sample of Answers to the Open-ended Question “What are
your Main Considerations about the Policy?”
OA-7.1 Income Taxation
Distribution: “That the rich and wealthy do not pay their fair share of taxes.”
“Everyone, including the rich and corporations should pay their fair share.”
“I would want working class and middle class people to get tax cuts and I’d be willing to pay more in taxes
for that to happen.”
Fairness: “I have trouble with the concept of tax brackets that punish an individual for being successful.”
“I believe Everyone should be taxed fairly and the most wealthy should not escape carrying their weight.”
OA-9
Government Spending: “Current tax rates being raised are a result of government mismanagement of
funds and over spending without appropriate oversight. Taxes really can’t effectively be lowered until govern-
ment spending is properly controlled.”
“I am okay with raising personal income tax to reduce deficit but not for entitlement programs.”
Social safety net: “What are the taxes going towards? I strongly believe in funding going towards education
and infrastructure.”
“Cut government spending on social welfare programs for lower taxes and privatize most government services
for lower taxes e.g., mail, law enforcement, parks, schools...”
Effiency: “I am concerned about the push to raise taxes on persons with higher incomes. I do believe in
trickle down economics and that government should pretty much keep their hands off.”
“I want the U.S. to be competitive for businesses, but also know there needs to be an appropriate amount of
money to fund the government necessities.”
Flat Tax: “We need a flat tax. Tax forms are complex.”
“I think tax Rates are not fairly representative for most taxpayers. I support a flat tax rate for all except the
totally disabled and indigent.”
Loopholes: “I think the more you make, the more you should pay. We need to close the loopholes that are
there to make sure that those who make more actually pay more.”
“The wealthy oligarchs who own this country will never allow their taxes to be raised, or will hire tax lawyers
to get out of paying them, so any raise in federal personal income taxes will fall on the middle class.”
Don’t know: “I don’t know much about this topic.”
OA-7.2 Estate Tax
Distribution: “It can help keep the ultra wealthy accountable for their wealth.”
“Passing wealth from one generation to the next contributes to wealth inequality. Federal estate tax should
be much higher.”
Fairness: “I don’t think there should be a federal estate tax because it’s kind of unfair to have to pay taxes
on money that already belongs to your family and has most likely had taxes paid on it already.”
Government spending: “I believe in smaller government, so all taxes should be lower. I actually think we
should have a flat tax for income - period. Then estate taxes wouldn’t even be an issue.”
Public goods: “I would like higher taxes to pay for more domestic spending such as education, healthcare,
etc.”
Efficiency: “Lower taxes mean I have more disposable income to spend therefore more products can be mad
and more jobs created. I feel it is wrong to penalize people for increased wealth.”
Loopholes: “The wealthy don’t ususally pay these taxes, they find a loophole. Why should my children have
to pay taxes on things I’ve already paid taxes on during my lifetime?”
Double taxation: “I think it is ridiculous, you pay taxes twice.”
Grief: “I don’t think we should have one at all. You’re taxing a family member for the death of their loved
one? That’s messed up.”
OA-10
OA-8 Additional Figures
Figure OA-1: Word clouds for the Income Tax
(a) What are your Main Considerations
about the Income Tax?
lower tax
higher tax
middle class
fair share
lower class
fair tax
working class
flat tax
tax people
people higher
lower people
higher higher
tax higher
lower middle
tax class
tax middle
class people
rich people
tax tax
rich tax
rich poor
upper class
higher lower
tax lower
people work
double tax
government spending
everyone fair
middle lower
people tax
tax good
everyone share
wealthy tax
tax high
higher people
government spend
work hard
cant afford
family tax
tax everyone
end meet
social security
working people
tax share
wealthy fair
national debt
people lower
poor people
tax wealthy
class class
class higher
people rich
higher class
across board
rich fair
government waste
lower government
higher wealthy
lower working
people spend
poor rich
very high
tax break
people people
class rich
rich rich
sales tax
higher rich
people afford
social program
high earner
class tax
tax government
wealthy people
lower lower
higher earner
tax poor
people high
poor class
tax rich
class poor
rich share
people struggle
universal healthcare
tax fair
take home
class middle
lower higher
people government
government good
people hard
tax level
good people
class upper
tax working
capital gain
many people
rich higher
everyone tax
middle people
very rich
people back
people cant
people fair
wealthy share
progressive tax
middle working
lower family
working middle
class lower
higher middle
level tax
lower good
tax economy
people take
take paycheck
high people
government control
nothing come
take away
tax benefit
wealthy higher
economic growth
close loophole
government program
good job
tax loophole
fair everyone
american people
paycheck paycheck
fair people
poor middle
support government
long term
hard people
tax always
people keep
government people
standard deduction
class too much
higher everyone
whether tax
hard earn
class fair
affect economy
two thousand
tax across
fund government
higher level
spend economy
class family
middle poor
people earn
working poor
government take
good economy
higher good
loophole wealthy
higher afford
tax low
poor lower
affect personally
take check
middle higher
upper middle
business business
affect family
fair rich
poor poor
hard working
double high
favor tax
president trump
poverty level
higher earn
everyone government
afford higher
tax afford
tax business
people working
government provide
low people
minimum wage
fifty thousand
working citizen
economy government
tax spend
many loophole
loophole rich
government fund
lower everyone
high low
different class
ten million
hundred thousand
break rich
class big
raise lowering
break working
people break
(b) What would be the Goal of a Good
Income Tax System?
flat tax
fair tax
lower tax
middle class
higher tax
fair share
tax tax
across board
lower class
tax everyone
tax bracket
everyone fair
rich poor
working class
everyone share
tax higher
lower middle
upper class
rich people
rich tax
higher higher
progressive tax
tax rich
sales tax
fair everyone
tax people
tax lower
tax class
class lower
flat everyone
tax middle
help people
fund government
hundred thousand
tax fair
tax deduction
wealthy people
class people
higher lower
tax share
higher rich
everyone equally
people higher
fair people
social security
provide service
lower lower
everyone tax
middle lower
rich fair
poor people
everyone regardless
people fair
poor middle
tax loophole
people people
lower people
people tax
wealthy fair
people lower
higher bracket
close loophole
people just
ensure everyone
people share
people live
people earn
large corporation
people afford
people fairly
slide scale
rich share
class upper
class poor
take consideration
rich rich
super rich
everyone matter
hard working
fund program
flat across
rich lower
everyone fairly
poor rich
loophole wealthy
balance budget
ten percent
class class
national sales
national tax
fair class
working people
go back
higher earner
everyone treat
allow people
social program
fair across
progressive higher
tax across
cant afford
loophole rich
flat deduction
tax wealthy
rich higher
poor class
take away
tax working
higher class
national debt
wealthy tax
people cant
lower higher
work hard
provide fund
cost live
thousand hundred
just rich
twenty five
higher wealthy
lower poor
people keep
very high
people help
lower bracket
help citizen
higher people
wealthy individual
help poor
healthcare education
bracket higher
take account
tax high
tax ten
government provide
fair rich
class tax
government program
tax low
people work
graduate higher
many people
working poor
people spend
tax government
tax poor
higher upper
dollar spend
two hundred
help government
everyone loophole
everyone deduction
government spending
everyone equal
loophole allow
board everyone
earn credit
eliminate loophole
class middle
tax board
tax easy
tax citizen
middle poor
fair equitable
wealthy share
rich help
fifty thousand
class wealthy
able afford
benefit people
minimum wage
working hard
just people
take people
free healthcare
quality life
capital gain
universal healthcare
tax business
loophole corporation
hundred fifty
support government
live paycheck
people accord
class rich
upper middle
wealthy afford
everyone accord
service provide
tax may
treat equally
fair equal
fair higher
share higher
run government
million dollar
go towards
few deduction
people working
twenty thousand
(c) What are the Shortcomings of the
Income Tax System?
too many loophole
middle class
fair share
rich poor
lower class
rich people
working class
rich rich
too many break
loophole rich
too many people
upper class
too many rich
loophole wealthy
people work
people avoid
too many wealthy
loophole people
avoid fair
rich avoid
poor poor
wealthy people
poor people
wealthy corporation
avoid share
middle lower
rich corporation
loophole corporation
loophole avoid
class people
rich fair
people people
take too much
lower people
government spending
cant afford
break rich
rich share
high earner
lower middle
rich middle
break wealthy
people fair
rich break
loophole fair
poor rich
people too much
work hard
big corporation
complicated too many
class too much
big business
poor middle
poor class
super rich
people cant
favor rich
people middle
favor wealthy
working people
class lower
too many deduction
feel like
rich keep
people rich
use avoid
people corporation
too much government
people use
wealthy avoid
complicated loophole
break people
class higher
higher bracket
class rich
class poor
high class
class class
large corporation
higher class
earn credit
donald trump
too much people
wealthy share
high bracket
everyone fair
everyone share
corporation wealthy
keep rich
high middle
take away
class upper
rich too much
people earn
loophole use
lower bracket
use thing
people higher
people hard
people share
higher earner
every year
poor too much
benefit rich
high people
very wealthy
fair people
wealthy fair
big break
people business
working poor
people lower
hard working
people like
people understand
too much class
wealthy too many
people live
complicated fair
too much waste
just rich
thousand dollar
come mind
government waste
break big
too much lower
lower family
too many avoid
find loophole
too many too many
break corporation
help people
rich lower
middle people
good people
people working
average person
people barely
take people
wealthy individual
benefit wealthy
class work
big company
capital gain
people loophole
people try
social security
two thousand
hundred thousand
people benefit
people very
fair middle
class high
very rich
let people
people cheat
people break
rich loophole
loophole lower
help class
fair everyone
class working
burden middle
people also
corporation avoid
hard earn
free free
corporation too many
class citizen
people want
working middle
people government
easy people
people nothing
too much spending
corporation share
just keep
million dollar
everyone else
people takeadvantage
wealthy loophole
people high
high low
loophole high
write offs
low end
far too many
too many corporation
corporation rich
people decision
super wealthy
people afford
very fair
rich too many
corporation people
too much take
loophole deduction
people receive
bracket fair
fair too many
OA-11
(d) Which important aspects of the U.S.
federal income tax system would you say
are not discussed enough in the current
policy debate?
middle class
lower class
working class
fair share
lower middle
social security
small business
rich poor
government spending
long term
loophole rich
big business
rich share
rich little
upper class
cost live
hard working
class rich
minimum wage
help middle
rich fair
rich avoid
close loophole
rich middle
large corporation
top one
poor class
class family
middle lower
big company
average american
rich corporation
national debt
loophole wealthy
loophole corporation
capital gain
higher bracket
class class
rich no
corporation wealthy
cant anything
working poor
business owner
every year
work hard
working middle
cut spending
higher class
class lower
high earner
wealthy break
effect lower
write offs
percentage take
large company
very rich
wealthy share
federal government
higher earner
wealthy fair
break corporation
break rich
action take
higher lower
average citizen
class wealthy
class too much
big corporation
help class
very wealthy
wealthy corporation
across board
cut wealthy
way too much
break big
take away
come mind
rich class
favor rich
one thousand
special interest
receive break
loophole avoid
loophole allow
benefit wealthy
class citizen
small owner
low class
class poor
right now
higher higher
low earner
break wealthy
raise rich
cut class
wealthy individual
lower working
(e) What do you think would be the
effects on the U.S. economy if the federal
personal income taxes were increased?
middle class
lower class
working class
hurt middle
lower middle
small business
poor class
negative impact
higher tax
end meet
middle lower
hurt lower
lower tax
across board
economic growth
class suffer
poor middle
government spending
consumer spending
hurt class
cant afford
decrease spending
working poor
class poor
quality life
cost live
national debt
able afford
live paycheck
class class
upper class
class struggle
spending decrease
put back
take hit
very bad
stock market
long run
class lower
already struggle
good service
rich poor
poor rich
lower spending
work hard
hard working
working middle
class rich
slow growth
social program
live check
fair share
good good
class family
tax bracket
lose home
class working
very good
right now
poor working
slow spending
lower working
tax class
good life
struggle end
negative affect
hard time
class middle
rich tax
class spending
hurt business
low class
minimum wage
find way
higher lower
working family
poverty level
hurt working
paycheck paycheck
affect rich
long term
spending good
lower bracket
spending hurt
working suffer
buy good
able buy
stop spending
government waste
social service
work government
buy power
lower suffer
class even
double tax
spending power
struggle meet
spending consumer
poor lower
struggle even
cut spending
credit card
good infrastructure
already live
lose job
use wisely
slow economic
poor suffer
class hard
spending government
universal healthcare
hurt already
class citizen
class hurt
cut back
affect lower
class afford
create job
hard end
stop working
afford live
house market
able bill
middle suffer
government just
hard live
very wealthy
stop buy
middle poor
move country
day day
government assistance
lower family
hurt poor
middle struggle
middle working
good use
rich find
lower consumer
good working
fund government
class worker
negative way
class work
discretionary spending
very negative
hard now
higher earner
give government
class see
good bad
good debt
government program
working american
few job
business suffer
super wealthy
government use
food stamp
poor even
lower deficit
reduce spending
negative lower
education healthcare
good quality
spending class
spending business
tax middle
economic slowdown
able live
take home
free market
class affect
hard middle
one hundred
class live
Notes: Word clouds based answers to open-ended questions stated in the caption. See Section OA-5.1.
OA-12

Figure OA-2: Distributional effects of Income Tax Increase: Who Gains if
Taxes on High Earners were to be Increased?
Notes: The figure reports raw frequencies among Democrat and Republican respondents of the groups mentioned when an-
swering to the question “Which groups of people do you think would gain if federal personal income taxes on high earners were
increased?”
OA-13
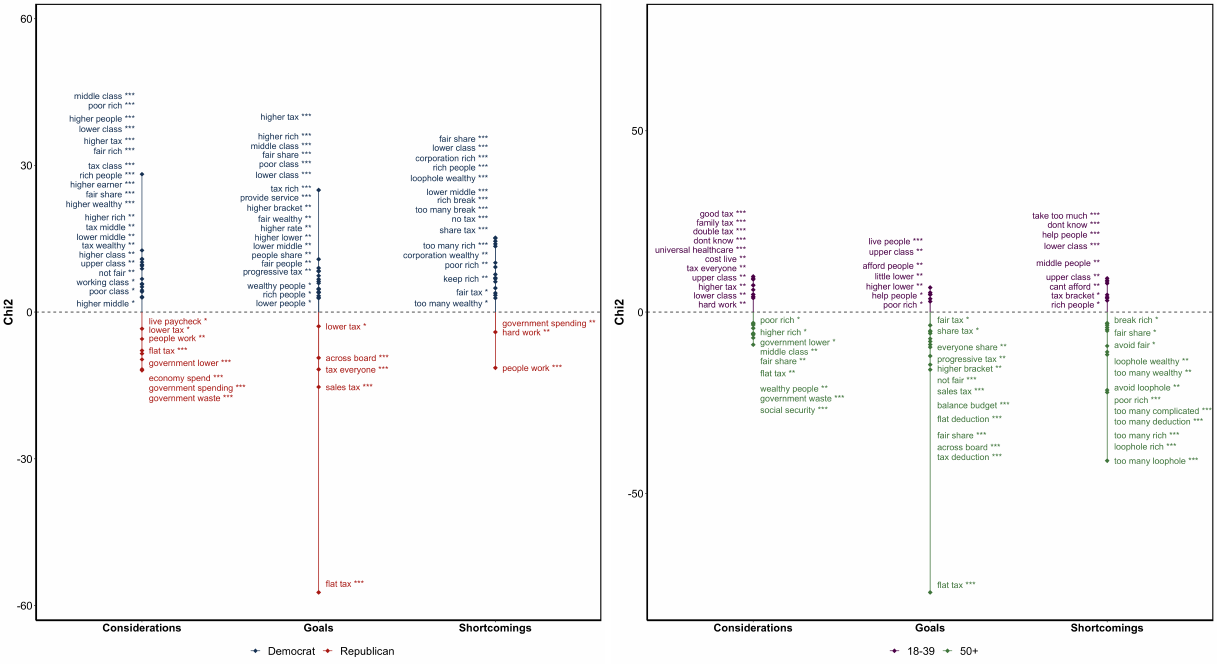
Figure OA-3: Keywords of Income Taxation by Groups
(a) By Political Affiliation (b) By Age Group
OA-14

(c) By Perceived Social Class (d) By Education Level
Notes: The figure shows keywords among different groups of respondents in answers to the questions about respondents’ main considerations, desired goals, and shortcomings
of the income tax. See Section OA-2 for the full text of the questions. The groups are defined by political affiliation, age, perceived social class, and education level, respectively.
The score reported for a set of two words is the χ
2
- test statistic, testing the null hypothesis that the occurrence of the given keywords is the same among the two groups. *
p < 0.1, ** p < 0.05, *** p < 0.01. See Section OA-5.2.
OA-15
Figure OA-4: Word clouds for the Estate Tax
(a) What are your Main Considerations
about the Estate Tax?
double tax
fair tax
middle class
family tax
lower class
lower tax
work hard
tax tax
tax twice
lower income
tax no tax
tax bracket
tax double
working class
income tax
higher lower
tax government
tax free
income bracket
government tax
lower family
fair share
higher income
government right
tax income
five million
cant afford
hundred thousand
wealthy tax
work life
low income
higher tax
tax higher
income family
transfer tax
upper class
tax high
tax transfer
family farm
left behind
higher rich
two thousand
higher higher
rich poor
good way
family government
lower high
tax time
cost live
wealthy family
way government
rich rich
lower higher
likely tax
middle lower
higher little
tax fair
rich tax
lower inherit
small business
wealthy higher
higher bracket
government family
afford higher
tax lower
family family
lower lower
tax inherit
ten million
since tax
income inherit
class lower
poor class
lower middle
family without
inherit tax
higher wealthy
lower government
capital gain
financial burden
tax way
transfer fund
bracket higher
save tax
family no tax
poor rich
burden family
hard work
asset tax
lower good
flat tax
family business
higher class
tax impose
lower work
lower poor
high income
tax asset
transfer higher
fair inherit
tax good
tax live
lower way
way lower
next generation
hard life
lose lovedone
little higher
whole life
slide scale
government transfer
first place
higher way
hard tax
ultra wealthy
tax died
income level
class family
entire life
wealthy fair
income income
rich higher
either way
hard family
wealthy income
lower since
high tax
no tax government
government revenue
financial situation
inherit large
hard save
lower burden
tax previously
life insurance
tax save
lower bracket
family generation
lower hard
lower afford
low family
tax wealthy
lowered tax
lower fair
government greedy
lower lose
large sum
tax since
exist tax
government double
lower no tax
no tax tax
government no tax
work save
class poor
belong family
life government
good government
eliminate tax
tax fund
family good
class afford
higher middle
higher transfer
work child
family work
owner tax
benefit wealthy
life work
farm business
work tax
work family
(b) What would be the Goal of a Good
Estate Tax System?
already tax
fair tax
five million
hundred thousand
twenty five
lower income
ten million
middle class
lower class
five hundred
five thousand
double tax
tax tax
fair share
five ten
across board
thousand five
fifty thousand
hundred fifty
thousand hundred
family tax
low income
million five
rich poor
fair everyone
wealthy people
million million
two million
twenty million
property tax
people live
higher higher
income people
rich people
slide scale
five five
fifty million
million ten
five fair
ten thousand
small percentage
capital gain
low possible
income tax
transfer heir
fifty five
twenty thousand
two hundred
tax people
lower people
flat tax
wealthy tax
thirty five
wealth transfer
noooalready tax
thousand twenty
wealthy family
ten five
middle lower
lower higher
work hard
fair people
anything million
income family
hundred twenty
income inherit
higher income
concentration wealth
allow people
help people
zero tax
high income
income already
million twenty
five fifty
family farm
tax higher
allow family
fair income
million fifty
hundred million
little little
lower middle
fifteen million
inherit wealth
something fair
tax income
twenty two
wealth heir
zero already
wealthy fair
people able
government spend
help government
treat income
rich tax
two five
five twenty
five thirty
ten twenty
everyone fairly
higher class
higher tax
right now
percentage income
little possible
little five
everyone fair
two thousand
no tax heir
two fifty
little fortunate
fifty fifty
wealthy share
ten fair
tax come
nothing government
depend size
ultra wealthy
left heir
inherit income
four hundred
public education
tax twice
class class
family family
help economy
fifty twenty
inheritance five
income lower
upper class
set percentage
help lower
thousand ten
none tax
receive inheritance
people tax
(c) What are the Shortcomings of the
Estate Tax System?
already tax
double tax
tax tax
too many loophole
fair tax
middle class
lower income
cant afford
two thousand
fair share
rich rich
tax twice
lower class
rich poor
loophole wealthy
high rate
favor rich
work hard
government spend
income family
wealth transfer
small business
find loophole
first place
loophole allow
able afford
property tax
answer question
working class
benefit wealthy
charge too much
family tax
lower middle
burden heir
family farm
just government
right now
income bracket
wealth tax
work life
seem fair
tax income
ultra wealthy
tax property
allow wealth
wealthy tax
transfer wealth
value asset
high limit
two eighteen
thousand eighteen
fair already
fair inherit
lose lovedone
many loophole
government too much
even exist
tax wealth
current system
too many rich
loophole rich
rate high
someone already
fair family
across board
family business
seem tax
tax since
tax many
tax earn
(d) What do you think would be the
effects on the U.S. economy if the
federal estate tax were increased?
middle class
lower class
find way
small business
lower income
already tax
negative impact
fund program
working class
government waste
good thing
fair share
negative affect
find loophole
find around
probably good
give government
economic growth
government little
low income
rich poor
little little
little good
able afford
little income
class lower
wealthy find
way around
revenue government
probably little
long run
just waste
upper class
move country
little job
family business
social program
just government
cause problem
government need
middle lower
help deficit
leave heir
long term
cant afford
poor middle
poor class
hard time
good wealthy
work hard
findway around
hurt little
good service
live paycheck
nothing government
national debt
way avoid
put back
create job
try hide
lot little
way leave
business farm
hurt class
family tax
farm business
help government
income government
government project
positive impact
good bad
right now
little home
leave country
fund social
impact overall
put government
good government
wealthy individual
little suffer
hurt family
either way
class class
help fund
bad government
little business
business business
negative little
good just
help debt
Notes: Word clouds based answers to open-ended questions stated in the caption. See Section OA-5.1.
OA-16

Figure OA-5: Keywords of Estate Tax by Groups
(a) By Political Affiliation
(b) By Age Group
higher lower *
income bracket **
dont know ***
income bracket *
two thousand **
dont know ***
already tax ***
double tax ***
tax free ***
already no tax ***
not fair ***
government tax **
not tax **
government right **
life work **
hard work *
higher rich *
tax twice *
zero percent ***
ten million *
double tax ***
already tax ***
not fair **
not tax *
−50
0
50
Considerations Goals Shortcomings
Chi2
18−39 50+
OA-17
(c) By Perceived Social Class
(d) By Education Level
Notes: The figure shows keywords among different groups of respondents in answers to the questions about respondents’ main
considerations, desired goals, and shortcomings of the estate tax. See Section OA-2 for the full text of the questions. The
groups are defined by political affiliation, age, perceived social class, and education level, respectively. The score reported for
a set of two words is the χ
2
- test statistic, testing the null hypothesis that the occurrence of the given keywords is the same
among the two groups. * p < 0.1, ** p < 0.05, *** p < 0.01. See Section OA-5.2.
OA-18

Figure OA-6: Distributional effects of Estate Tax Increase: Who Loses if
the Estate Tax were Increased?
Notes: The figure reports raw frequencies among Democrat and Republican respondents of the groups mentioned when answer-
ing to the question “Which groups of people do you think would lose if the federal estate tax were increased?”
OA-19

Figure OA-7: Probability of Mentioning Topics
(a) Income Tax
OA-20

(b) Estate Tax
0
5
10
15
Probability (%)
Distribution Fairness Gov. Spending Efficiency Loopholes Double Tax Grieve Public Goods Don't Know
Main Considerations about Estate Tax? Goals of a Good Estate Tax System? Shortcomings of Estate Tax System?
Notes: The figure presents, based on the keyword-based topic analysis, the probability of mentioning topics for three open-ended
income and estate tax questions. Each reported topic corresponds to an indicator variable in the keyword-count model, which
equals 1 if the respondent mentions in their response at least one of the topic-defining keywords. For the list of keywords and
details on the text analysis methodology, see Section OA-6 and see Section OA-5.3. Panel A: Considerations: When you think
about federal personal income taxation and whether the U.S. should have higher or lower federal personal income taxes, what
are the main considerations that come to your mind?; Goals: What would be the goal of a good tax system?; Shortcomings:
What do you think are the issues with or shortcomings of the U.S. federal income tax system? Panel B: Considerations: When
you think about the federal estate tax and whether the U.S. should have a higher or a lower federal estate tax, what are the
main considerations that come to your mind?; Goals: What would be the goal of a good estate tax system?; Shortcomings:
What do you think are the shortcomings of the U.S. federal estate tax? For details on the text analysis methodology, see Section
OA-5.3.
OA-21

Figure OA-8: Topic Distribution by Political Affiliation for the Income
Tax
(a) What are your Main Considerations about the U.S. federal income tax system?
0
10
20
30
40
50
Distribution
0
10
20
30
40
50
Fairness
0
10
20
30
40
50
Gov. Spending
0
10
20
30
40
50
Social Safety
0
10
20
30
40
50
Efficiency
0
10
20
30
40
50
Flat Tax
0
10
20
30
40
50
Loopholes
0
10
20
30
40
50
Public Goods
0
10
20
30
40
50
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
(b) What would be the goal of a good income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
(c) What do you think are the shortcomings of the U.S. federal income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
Notes: The figure shows distribution of topics mentioned in the answers to the open-ended questions about the income tax by
political affiliation. See Section OA-2 for the full text of the questions. The bars represent the number of times a topic was
mentioned out of the total mentions of any topic by political group. For the list of keywords and details on the methodology,
see Section OA-6 and see Section OA-5.3.
OA-22

Figure OA-9: Topic Distribution by Income Groups for the Income Tax
(a) What are your Main Considerations about the U.S. federal income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Low income Middle income High income
(b) What would be the goal of a good income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Low income Middle income High income
(c) What do you think are the shortcomings of the U.S. federal income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Low income Middle income High income
Notes: See the notes to Figure OA-8. Low income (High income) corresponds to respondents who report a pre-tax household
income below (above) 39,000 (70,000) U.S. dollars; Medium income corresponds to respondents who report a pre-tax household
income between 40,000 and 69,000 U.S. dollars.
OA-23

Figure OA-10: Topic Distribution by Age Group for the Income Tax
(a) What are your Main Considerations about the U.S. federal income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
(b) What would be the goal of a good income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
(c) What do you think are the shortcomings of the U.S. federal income tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Social Safety
0
10
20
30
40
Efficiency
0
10
20
30
40
Flat Tax
0
10
20
30
40
Loopholes
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
Notes: See the notes to Figure OA-8.
OA-24

Figure OA-11: Topic Distribution by Political Affiliation of the Estate Tax
(a) What are your Main Considerations about the U.S. federal estate tax system?
0
10
20
30
40
50
Distribution
0
10
20
30
40
50
Fairness
0
10
20
30
40
50
Gov. Spending
0
10
20
30
40
50
Efficiency
0
10
20
30
40
50
Loopholes
0
10
20
30
40
50
Double Tax
0
10
20
30
40
50
Grieve
0
10
20
30
40
50
Public Goods
0
10
20
30
40
50
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
(b) What would be the goal of a good estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
(c) What do you think are the shortcomings of the U.S. federal estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Clinton Liberal Clinton Moderate Trump Moderate Trump Conservative
Notes: See the notes to Figure OA-8.
OA-25

Figure OA-12: Topic Distribution by Income Groups of the Estate Tax
(a) What are your Main Considerations about the U.S. federal estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Low income Middle income High income
(b) What would be the goal of a good estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0
10
20
30
40
Don't Know
Low income Middle income High income
(c) What do you think are the shortcomings of the U.S. federal estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public
0
10
20
30
40
Don't Know
Low income Middle income High income
Notes: See the notes to Figure OA-9.
OA-26

Figure OA-13: Topic Distribution by Age Group of the Estate Tax
(a) What are your Main Considerations about the U.S. federal estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
(b) What would be the goal of a good estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
(c) What do you think are the shortcomings of the U.S. federal estate tax system?
0
10
20
30
40
Distribution
0
10
20
30
40
Fairness
0
10
20
30
40
Gov. Spending
0
10
20
30
40
Efficiency
0
10
20
30
40
Loopholes
0
10
20
30
40
Double Tax
0
10
20
30
40
Grieve
0
10
20
30
40
Public Goods
0 10 20 30 40
Don't Know
Age 18-29 Age 30-49 Age 50-69
Notes: See the notes to Figure OA-8.
OA-27
References
Agrawal, A., W. Fu, and T. Menzies (2018). What is wrong with topic modeling? And how to fix it using
search-based software engineering. Information and Software Technology 98, 74–88.
Baeza-Yates, R., B. Ribeiro-Neto, et al. (1999). Modern information retrieval, Volume 463. ACM press New
York.
Banerjee, S., K. Ramanathan, and A. Gupta (2007). Clustering short texts using wikipedia. In Proceedings
of the 30th annual international ACM SIGIR conference on Research and development in information
retrieval, pp. 787–788.
Benoit, K., K. Watanabe, H. Wang, P. Nulty, A. Obeng, S. M¨uller, and A. Matsuo (2018). Quanteda: An r
Package for the Quantitative Analysis of Textual Data. Journal of Open Source Software 3 (30), 774.
Blei, D., A. Ng, M. Jordan, and J. Lafferty (2003, 02). Journal of machine learning research 3 (2003) 993-1022
submitted 2/02; published 1/03 latent dirichlet allocation.
Blei, D. M. and D. Jon (2007). Mcauliffe. supervised topic models. Advances in Neural Information Processing
Systems 20, 121128.
Blei, D. M. and J. D. Lafferty (2006). Dynamic topic models. In Proceedings of the 23rd international
conference on Machine learning, pp. 113–120.
Deerwester, S., S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman (1990). Indexing by latent
semantic analysis. Journal of the American society for information science 41 (6), 391–407.
Flood, S., M. King, R. Rodgers, S. Ruggles, and J. R. Warren (2020). Integrated public use microdata
series, current population survey: Version 8.0 [dataset]. Minneapolis, MN: IPUMS. https://doi.org/
10.18128/D030.V8.0.
Gabrielatos, C. (2018, 02). Keyness analysis: Nature, metrics and techniques, pp. 225–258.
Gabrielatos, C. and A. Marchi (2011). Keyness: Matching metrics to definitions. In Theoretical-
methodological challenges in corpus approaches to discourse studies and some ways of addressing them.
Gallagher, R. J., K. Reing, D. Kale, and G. Ver Steeg (2017). Anchored correlation explanation: Topic mod-
eling with minimal domain knowledge. Transactions of the Association for Computational Linguistics 5,
529–542.
Gallup (2019). Party Affiliation, In Depth: Topics A to Z. https://news.gallup.com/poll/15370/
party-affiliation.aspx.
Gentzkow, M. and J. M. Shapiro (2010). What Drives Media Slant? Evidence from US Daily Newspapers.
Econometrica 78 (1), 35–71.
Heimerl, F., S. Lohmann, S. Lange, and T. Ertl (2014). Word Cloud Explorer: Text Analytics Based on
Word Clouds. In 2014 47th Hawaii International Conference on System Sciences, pp. 1833–1842.
Hofmann, T. (1999). Probabilistic latent semantic indexing. In Proceedings of the 22nd annual international
ACM SIGIR conference on Research and development in information retrieval, pp. 50–57.
Kilgarriff, A. (2001). Comparing corpora. International journal of corpus linguistics 6 (1), 97–133. Publisher:
John Benjamins.
Leech, G. and R. Fallon (1992). Computer corpora-what do they tell us about culture. ICAME journal 16.
Leip, D. (2019). Election Results from the Associated Press. Atlas of U.S. Presidential Elections and David
Wasserman of the Cook Political Report. https://uselectionatlas.org/RESULTS/.
Lu, B., M. Ott, C. Cardie, and B. K. Tsou (2011). Multi-aspect sentiment analysis with topic models. In
2011 IEEE 11th international conference on data mining workshops, pp. 81–88. IEEE.
Partington, A. (2014). Mind the gaps: The role of corpus linguistics in researching absences. International
Journal of Corpus Linguistics 19 (1), 118–146.
OA-28
Roberts, M. E., B. M. Stewart, D. Tingley, E. M. Airoldi, et al. (2013). The structural topic model and
applied social science. In Advances in neural information processing systems workshop on topic models:
computation, application, and evaluation, Volume 4, pp. 1–20. Harrahs and Harveys, Lake Tahoe.
Roberts, M. E., B. M. Stewart, D. Tingley, C. Lucas, J. Leder-Luis, S. K. Gadarian, B. Albertson, and D. G.
Rand (2014). Structural topic models for open-ended survey responses. American Journal of Political
Science 58 (4), 1064–1082.
Salton, G. and M. J. McGill (1983). Introduction to modern information retrieval. mcgraw-hill.
Sch¨onhofen, P. (2009). Identifying document topics using the wikipedia category network. Web Intelligence
and Agent Systems: An International Journal 7 (2), 195–207.
Stantcheva, S. (2021). Understanding tax policy: How do people reason? The Quarterly Journal of Eco-
nomics 136 (4), 2309–2369.
Stubbs, M. (2010). Three concepts of keywords. Keyness in texts, 21–42.
Tang, J., Z. Meng, X. Nguyen, Q. Mei, and M. Zhang (2014, 22–24 Jun). Understanding the limiting factors
of topic modeling via posterior contraction analysis. In E. P. Xing and T. Jebara (Eds.), Proceedings of
the 31st International Conference on Machine Learning, Volume 32 of Proceedings of Machine Learning
Research, Bejing, China, pp. 190–198. PMLR.
Taylor, C. (2013). Searching for similarity using corpus-assisted discourse studies. Corpora 8 (1), 81–113.
Watanabe, K. (2018a). Conspiracist propaganda: How russia promotes anti-establishment sentiment online.
In ECPR General Conference, Hamburg.
Watanabe, K. (2018b, March). Newsmap: A semi-supervised approach to geographical news classification.
Digital Journalism 6 (3), 294–309.
Watanabe, K. and Y. Zhou (2020). Theory-driven analysis of large corpora: Semisupervised topic classifica-
tion of the un speeches. Social Science Computer Review, 0894439320907027.
OA-29
